在当今人工智能的快速发展中,AI模型相互融合已成为提升系统性能的关键策略,模型融合是指将多个独立的AI模型组合起来,共同解决一个问题,从而发挥各自的优势,弥补单一模型的不足,这种方法不仅提高了预测的准确性,还增强了系统的鲁棒性,使其在面对复杂数据时更可靠,对于网站访客来说,理解模型融合的实用方法,能帮助你在实际项目中更高效地部署AI解决方案,我将详细介绍模型融合的核心概念、操作步骤以及实际应用场景,最后分享我的个人观点。
模型融合的基本原理和方法
模型融合的核心在于利用多个模型的“集体智慧”,想象一下,如果让一群专家各自独立分析数据,再综合他们的意见,结果往往比单一个体更准确,在AI领域,这通过多种技术实现,最常见的方法包括集成学习(如bagging和boosting)、堆叠(stacking)以及模型平均。
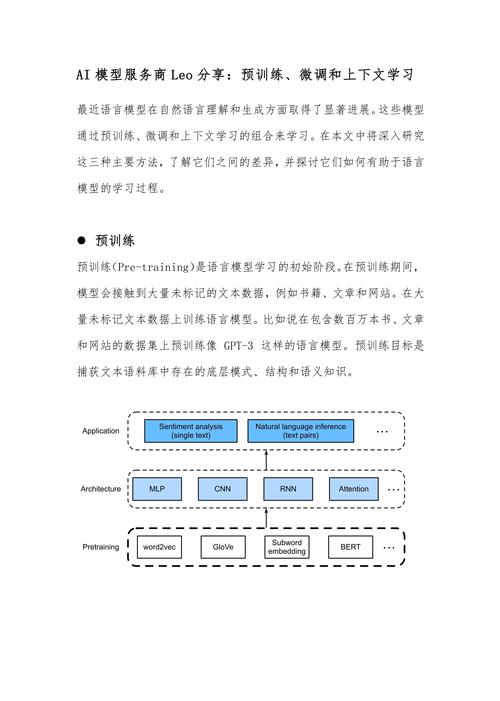
-
集成学习(Ensemble Learning):这是入门级融合技术,Bagging方法,例如随机森林(Random Forest),通过训练多个决策树模型,让它们投票决定最终输出,每个模型在训练时使用不同的数据子集,减少过拟合风险,Boosting方法,如XGBoost或LightGBM,则让模型逐步学习错误,前一个模型的误差被后一个模型重点纠正,逐步提升整体性能,这些方法简单易用,适合初学者在分类或回归任务中快速部署。
-
堆叠(Stacking):这是一种更高级的融合策略,它涉及训练多个“基础模型”(如SVM、神经网络或决策树),然后将它们的预测结果作为输入,训练一个“元模型”来做出最终决策,在图像识别中,你可以先用卷积神经网络(CNN)提取特征,再用支持向量机(SVM)进行分类,最后用一个逻辑回归模型整合输出,堆叠能捕捉模型间的互补性,但需要更多计算资源。

-
模型平均(Model Averaging):对于回归问题,简单地对多个模型的预测取平均值或加权平均,就能显著降低方差,在房价预测中,结合线性回归、梯度提升树和神经网络的输出,通过平均化得到更稳定的结果,这种方法计算高效,适合实时系统。
无论采用哪种方法,模型融合的关键是确保基础模型具备多样性,如果所有模型都相似,融合效果会大打折扣,在训练阶段,要使用不同的算法、数据采样或超参数设置,来增加模型的异质性。

如何在实际项目中应用模型融合
要将模型融合付诸实践,遵循系统化的步骤至关重要,下面,我将以自然语言处理(NLP)任务为例,逐步指导你如何操作,假设目标是构建一个情感分析系统,判断用户评论的正面或负面倾向。
-
定义问题并选择基础模型:明确你的任务类型(如分类、回归或聚类),对于情感分析,这是一个二分类问题,选择3-5个基础模型,确保它们各有优势。
- 一个基于BERT的预训练模型,擅长捕捉语义上下文。
- 一个简单的朴素贝叶斯分类器,计算速度快。
- 一个LSTM神经网络,处理序列数据效果好。 多样性是核心,避免模型同质化。
-
训练和验证基础模型:使用同一份数据集(如IMDB影评数据集)独立训练每个模型,划分训练集和验证集(70%训练,30%验证),通过交叉验证评估性能,记录每个模型的准确率、召回率等指标,这一步确保每个模型都达到可接受水平,避免弱模型拖累整体。
-
融合模型并训练元模型:采用堆叠方法,将验证集上的预测结果作为新特征输入,训练一个元模型(如随机森林或逻辑回归)。
- 基础模型预测:BERT输出概率0.8(正面),朴素贝叶斯输出0.6,LSTM输出0.7。
- 元模型将这些概率组合,通过训练学习权重,输出最终情感得分。
在Python中,可以用scikit-learn库的
StackingClassifier轻松实现。
-
评估和优化融合系统:在测试集上验证融合模型的性能,比较融合前后的指标——融合能将准确率提升5-10%,如果效果不佳,检查模型多样性:尝试添加更多算法(如决策树或KNN),或调整超参数,对于资源有限的项目,模型平均更实用:直接用加权平均(权重基于验证集表现)输出结果。
-
部署到生产环境:将融合模型封装为API或集成到应用中,使用工具如TensorFlow Serving或Flask框架,确保高效推理,监控系统性能,定期用新数据微调模型,防止概念漂移。
这个流程适用于各种场景,在医疗诊断中,融合CNN和Transformer模型能提高肿瘤检测精度;在金融风控中,结合逻辑回归和梯度提升树可降低误报率,模型融合不是万能药——它适合高精度需求的任务,但对于简单问题,单一模型可能更经济。
模型融合的好处与潜在挑战
模型融合的最大优势是提升泛化能力,单一模型易受数据噪声或偏差影响,而融合后系统更稳健,错误率更低,Kaggle竞赛中,优胜方案常依赖模型融合来实现微小但关键的提升,它支持模块化设计,便于团队协作:不同成员负责不同模型,最后整合输出。
挑战也不容忽视,计算成本显著增加——训练多个模型和元模型需要更多时间和硬件资源,尤其在大数据场景,模型复杂性也带来调试困难:如果某个基础模型失效,整个系统可能崩溃,初学者应从简单集成(如bagging)开始,逐步进阶,另一个风险是过拟合:如果融合不当,元模型可能放大噪声,通过正则化技术或早停策略来缓解。
实际应用案例与启示
模型融合已在多个领域落地生根,以自动驾驶为例,特斯拉的系统融合了计算机视觉模型(识别物体)、强化学习模型(决策路径)和时间序列模型(预测轨迹),综合输出安全指令,在电商推荐系统中,阿里巴巴融合协同过滤和深度学习模型,精准预测用户偏好,提升转化率,这些案例证明,模型融合不仅是理论概念,更是驱动商业价值的引擎。
对于个人开发者或中小企业,开源工具降低了门槛,利用Hugging Face的Transformers库或Google的TensorFlow,你能快速实验融合方案,建议从小项目入手:比如用Python构建一个融合模型预测房价,测试不同组合的效果,积累经验后,再扩展到复杂应用。
AI模型相互融合是智能系统进化的必经之路,它教会我们,协作胜于单打独斗——在技术世界如此,人生亦然,拥抱融合思维,你将解锁AI的无限潜力,创造更可靠的解决方案,随着边缘计算和联邦学习的发展,模型融合会更轻量化、隐私友好,成为AI民主化的核心驱动力,这是我的坚定信念:融合不只是一种技术,更是推动创新的哲学。

 13888888888
13888888888

 点击咨询
点击咨询 