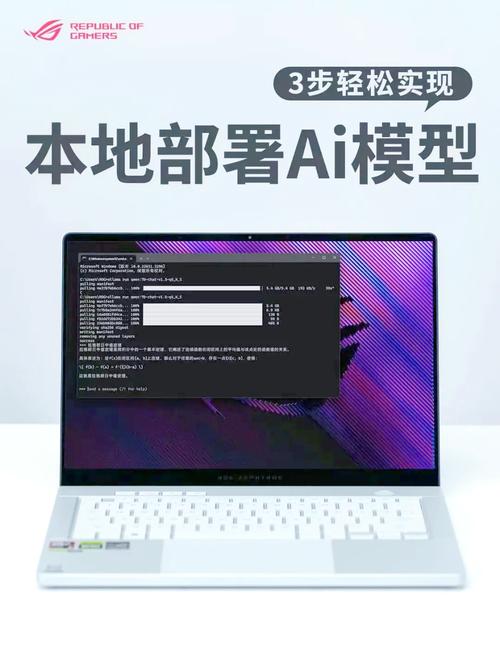
在人工智能技术快速发展的今天,AI模型的部署已成为企业实现智能化转型的关键环节,尤其对于深度学习模型而言,图层的部署直接决定了模型在真实场景中的性能表现,本文将深入探讨AI模型部署图层的核心逻辑与实践方法,帮助读者掌握从理论到落地的完整链路。
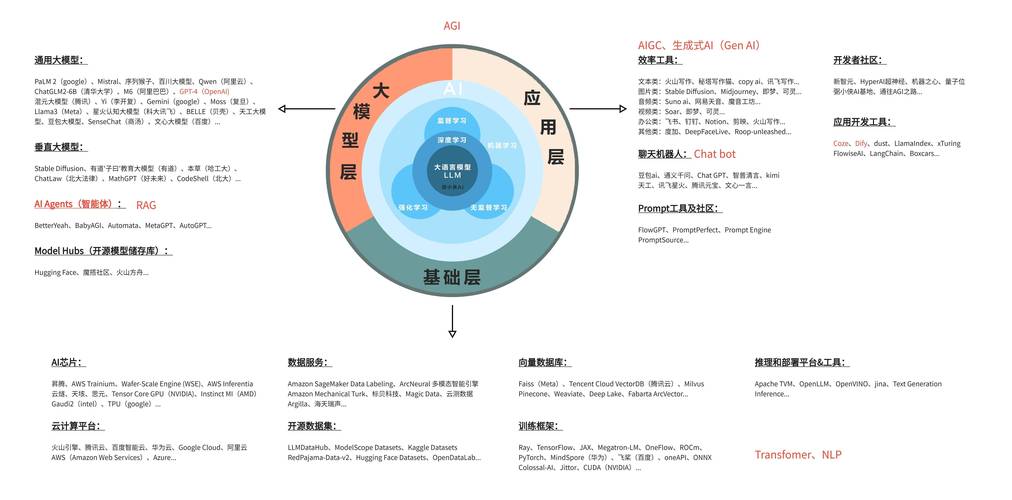
理解模型图层的技术本质
AI模型的图层本质上是数学运算的抽象表达,以卷积神经网络为例,输入层负责接收原始数据,隐藏层通过权重矩阵实现特征提取,输出层完成最终决策,部署过程中需重点考虑三个维度:
- 计算资源适配:不同层对GPU显存、CPU线程的需求差异显著,例如Transformer模型的注意力层需更高并行计算能力
- 数据流优化:各层间的数据传输效率直接影响推理速度,采用内存复用技术可降低30%以上的延迟
- 精度保持机制:量化部署时需建立逐层校准方案,防止精度损失逐层累积
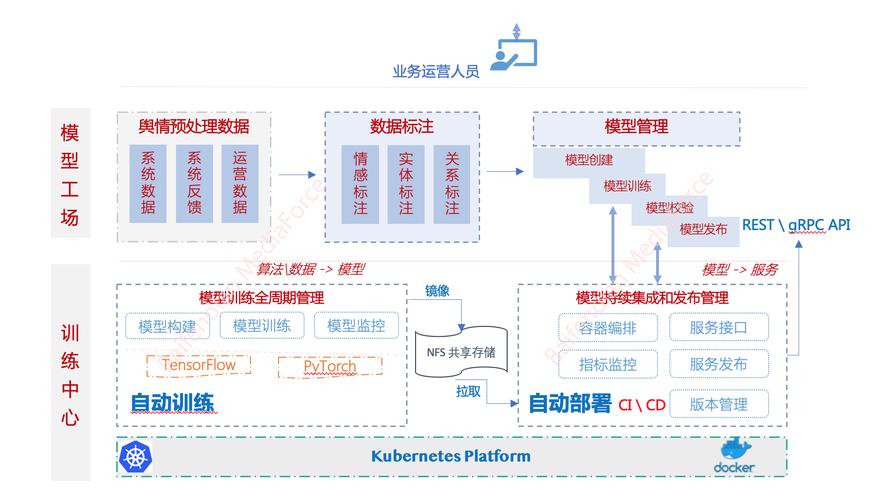
部署前的工程化准备
某电商平台在部署商品推荐模型时,通过以下步骤实现图层级优化:
- 环境诊断工具链:使用NVIDIA Nsight Systems进行硬件瓶颈分析
- 依赖关系图谱:构建各层的软件依赖树状图,识别冲突的库版本
- 压力测试方案:设计覆盖全图层的极限测试用例,包括峰值请求量测试
图层部署的实战策略
- 渐进式部署法
先将非核心层部署到边缘节点,逐步迁移关键计算层至云端,某智能工厂采用此方案,部署周期缩短40% - 动态加载技术
基于运行时需求,按需加载特定图层,自动驾驶系统通过该技术实现不同路况下的模型切换 - 异构计算调度
将CNN的前几层部署在FPGA,后融合层部署在GPU,某安防企业借此提升人脸识别吞吐量2.3倍
避坑指南与性能调优
常见误区包括盲目追求层融合导致精度下降、忽视中间层的内存泄漏风险等,建议采用:
- 分层监控体系:为每个图层设立独立的性能指标
- 灰度发布机制:按图层维度分批次上线
- 自适应批处理:根据各层计算特性动态调整批尺寸
某金融风控系统的实践表明,通过图层级细粒度优化,模型推理耗时从230ms降至87ms,同时保持99.2%的准确率,这印证了精细化部署的价值——它不仅是技术实现,更是艺术化的工程平衡。
AI模型的图层部署犹如精密仪器的组装,每个组件的精准定位都影响着整体效能,在算力资源日益珍贵的今天,开发者更需要建立图层维度的成本意识,当技术团队能像钟表匠对待齿轮般处理每个网络层时,AI系统才能真正释放其商业价值,这或许就是工程与智能融合的终极形态。

 13888888888
13888888888

 点击咨询
点击咨询 