人工智能技术的飞速发展离不开底层硬件的支持,而芯片作为算力的核心载体,其使用方式直接影响AI模型的训练效率和实际应用效果,本文将深入探讨AI模型与底层芯片的协同关系,并解析如何在不同场景中最大化发挥芯片性能。
AI模型与芯片的共生关系
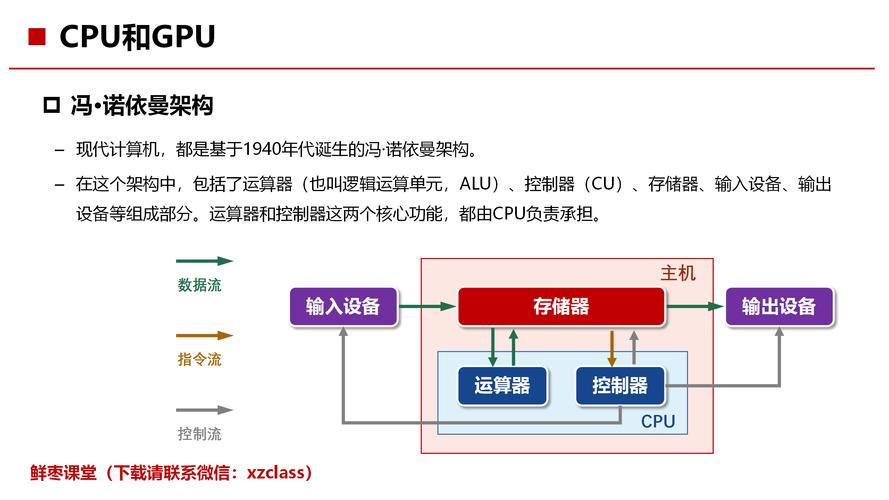
现代AI模型的复杂度呈指数级增长,以Transformer架构为基础的大语言模型(LLM)参数量动辄达到百亿甚至千亿级别,这类模型的训练和推理过程需要处理海量矩阵运算,传统CPU已无法满足需求,而GPU、TPU、ASIC等专用芯片凭借并行计算能力成为主流选择。
以英伟达A100 GPU为例,其搭载的第三代Tensor Core可加速混合精度计算,在训练ResNet-50模型时效率较前代提升20倍,这种硬件迭代直接降低了模型开发的时间成本和经济成本。
芯片使用场景的精细化匹配
训练阶段:集群化算力调度
模型训练对算力需求最高,通常需要搭建GPU集群,Meta训练Llama 3时使用了超过24000块H100 GPU,此时需关注:
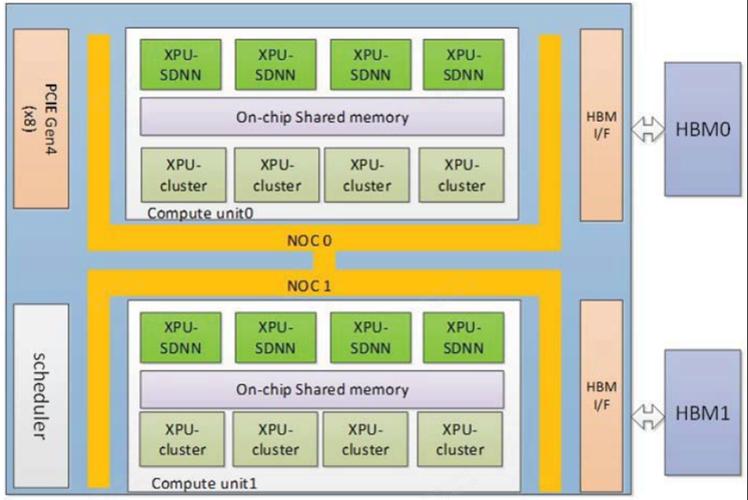
- 拓扑结构优化:NVLink高速互联技术可减少多卡通信延迟,避免计算资源闲置
- 显存管理:采用梯度累积、模型并行等技术突破单卡显存限制
- 能耗比控制:动态电压频率调节(DVFS)技术可降低30%功耗
推理阶段:场景化硬件部署
模型落地时需根据场景选择芯片:
- 云端推理:采用A100/V100等高性能GPU,支持高并发请求
- 边缘计算:使用Jetson系列等低功耗芯片,满足实时性要求
- 终端设备:NPU(神经网络处理器)集成于手机、摄像头,实现离线推理
谷歌TPUv4在部署BERT模型时,响应时间缩短至2毫秒,较CPU方案提升50倍,印证了专用芯片的价值。
性能调优的关键技术
计算图优化
通过算子融合减少内存访问次数,例如将Conv+BN+ReLU合并为单一算子,在华为昇腾芯片上可提升18%推理速度。
量化压缩
FP16混合精度训练已成为行业标准,部分场景可使用INT8量化,高通骁龙8 Gen3的AI引擎通过8位量化,在Stable Diffusion推理中保持画质同时提速3倍。
编译器优化
XLA(Accelerated Linear Algebra)编译器可将TensorFlow计算图转换为针对特定芯片的机器码,AMD MI300X通过ROCm软件栈实现与CUDA生态的性能对标。
行业实践中的挑战与突破
内存墙难题
芯片算力增长与内存带宽不匹配问题突出,HBM3高带宽内存的应用使海力士芯片达到819GB/s带宽,配合模型剪枝技术,可将百亿参数模型装入单卡。
软硬协同创新
特斯拉Dojo芯片采用分布式计算架构,配合自研编译器,使自动驾驶模型的训练周期从数月缩短至1周,这种从指令集到算法层的深度适配,创造了14倍于GPU集群的性价比优势。
能效比竞赛
绿色计算趋势推动芯片设计革新,Graphcore的IPU采用3D封装技术,在自然语言处理任务中实现每瓦特算力提升40%,为数据中心节省百万级电费开支。
未来演进方向
当芯片制程逼近物理极限,架构创新成为突破口,Cerebras的晶圆级引擎WSE-3通过85万个核心实现万亿参数模型的分布式训练,而光子芯片则有望突破现有冯·诺依曼架构的瓶颈,值得关注的是,开源指令集RISC-V正在催生新一代AI专用芯片,预计2025年相关市场规模将突破300亿美元。
在医疗影像分析领域,我们已见证定制化芯片如何将CT扫描诊断时间从小时级压缩到分钟级;在金融风控场景,量化交易模型通过FPGA加速实现微秒级响应,这些实践印证了一个事实:芯片不是简单的算力容器,而是承载AI落地的技术基座,当开发者深入理解芯片特性,针对性地设计模型结构和训练策略,才能真正释放人工智能的商业价值与社会价值。

 13888888888
13888888888

 点击咨询
点击咨询 