AI模型如何突破算力瓶颈?深度解析软硬件协同之道
人工智能模型正以前所未有的速度重塑世界,但驱动这些智能的引擎——硬件——却常常被忽视,从精准识别人脸的手机应用,到预测极端天气的超级计算机,AI能力的每一次飞跃,都离不开底层硬件的强力支撑,AI模型究竟如何与硬件深度结合,释放其真正的潜力?
硬件:AI模型落地的基石与加速器
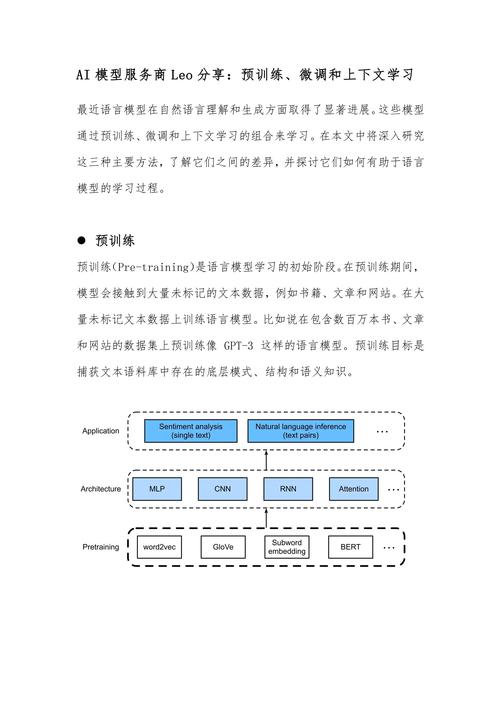
强大的AI模型,尤其是深度学习模型,堪称“计算巨兽”,训练一个如GPT-3这样的模型,动辄消耗数千个高端GPU数周甚至数月的计算资源,电力消耗堪比一个小型城镇,推理过程虽相对轻量,但在实时应用场景(如自动驾驶、视频分析)中,对硬件的响应速度和效率要求极高,硬件不仅是模型运行的物理载体,更是决定其性能上限、能效比和最终能否落地的关键瓶颈。
驱动AI的三大核心硬件支柱
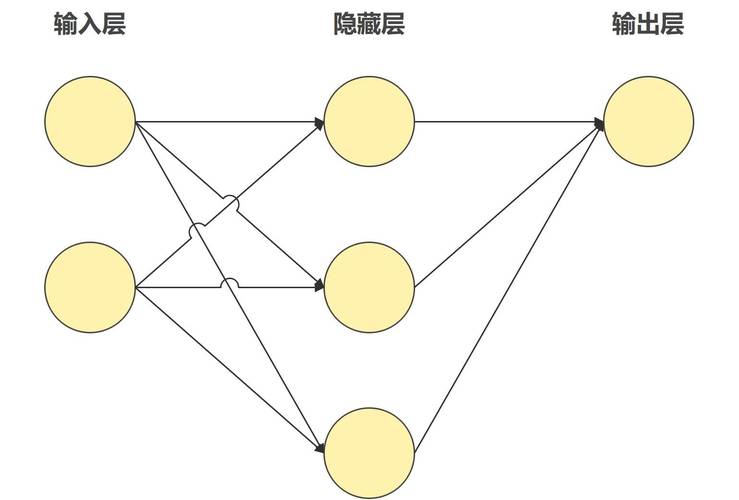
-
处理器:算力的心脏
- GPU(图形处理器): 凭借其大规模的并行计算核心架构,GPU天生擅长处理AI模型训练和推理中高度并行的矩阵运算(如卷积、矩阵乘法),它们已成为AI加速的标配,NVIDIA的CUDA生态是典型代表。
- TPU(张量处理器): 谷歌专为AI负载设计的ASIC芯片,TPU直接针对神经网络中最常见的张量操作进行硬件级优化,在特定AI任务(尤其是谷歌自身服务)上能效比和速度远超通用GPU。
- FPGA(现场可编程门阵列): 硬件逻辑可在制造后重新配置,提供高度的灵活性,适用于算法尚未完全固化、需要快速迭代或对特定计算模式有极致优化需求的场景,云服务商常用FPGA提供可定制的AI加速实例。
- 专用AI芯片(ASIC): 如华为昇腾、寒武纪思元等,这类芯片从设计之初就为AI计算量身定制,在目标应用上(如计算机视觉、自然语言处理)可实现最优的性能功耗比,是边缘设备(手机、摄像头)部署AI的关键。
-
存储:数据的生命线
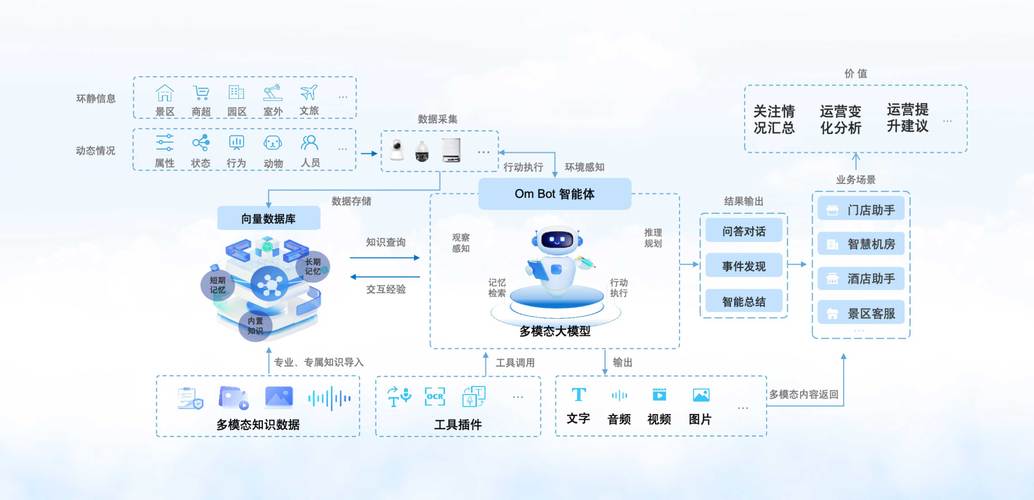
- 高带宽内存(HBM): AI模型处理海量参数和数据,对内存带宽需求巨大,HBM采用先进的3D堆叠技术,通过硅中介层与处理器紧耦合,提供远超传统GDDR内存的带宽,有效缓解“内存墙”问题,成为高端AI芯片(如NVIDIA H100, AMD MI300)的标配。
- 大容量DRAM: 训练大型模型需要装载巨大的数据集和模型参数,充足的内存容量是基础保障。
- 存储层级优化: 利用高速缓存(Cache)、非易失性内存(如Intel Optane)等技术,构建更高效的数据访问路径,减少等待时间。
-
互联:规模化的血脉
- 高速互联技术: 单颗芯片算力有限,训练超大模型或进行大规模推理必须依赖多芯片/多机协作,NVIDIA NVLink、InfiniBand等技术提供远超传统以太网的超低延迟、高带宽连接,使数千甚至数万颗GPU能够高效协同,如同一个巨型计算引擎,这是构建AI超级计算机的核心。
软硬协同:释放1+1>2的效能
硬件是舞台,软件是指挥,两者的深度协同优化,才能奏响AI高性能的乐章:
- 框架与编译器优化: TensorFlow, PyTorch等主流AI框架持续集成针对不同硬件(GPU/TPU/CPU)的优化内核,编译器技术(如MLIR, TVM)能将高级模型描述高效编译并优化到特定硬件指令集上,充分利用硬件特性。
- 模型量化与剪枝: 将模型参数从高精度浮点(如FP32)转换为低精度格式(如INT8, FP16),显著降低计算量和内存占用,尤其利于边缘端部署,模型剪枝则移除冗余参数,生成更轻量的模型,这些技术需要硬件支持相应的低精度计算指令。
- 专用指令集: 如ARM的SVE/SVE2、x86的AVX-512/VNNI、以及各AI加速芯片的自定义指令集,直接提供针对AI基本操作的硬件加速指令,大幅提升效率。
- 近内存/存内计算: 突破传统冯·诺依曼架构瓶颈的创新方向,将部分计算单元嵌入存储单元内部或附近,直接在数据存储位置进行计算,极大减少数据搬运的能耗和延迟,是未来超高效能比AI硬件的重要探索方向。
融合的挑战与未来之路
AI与硬件的结合并非坦途,日益复杂的模型架构持续挑战硬件设计极限;通用性与专用性的平衡(ASIC高效但灵活度低,CPU/GPU灵活但效率受限)是永恒课题;不同硬件平台间的生态割裂增加了开发部署成本;高昂的硬件投入和能源消耗呼唤更高的能效比。
斯坦福大学以人为本人工智能研究所(HAI)2023年报告指出,顶尖AI模型的训练算力需求每6-10个月翻一番,这一趋势推动着硬件创新的加速:
- Chiplet(小芯片)与先进封装: 将大型单芯片拆分为多个功能化小芯片,通过先进封装(如3D封装、CoWoS)集成,提升良率、设计灵活性和性能。
- 光计算/硅光互联: 利用光子传输数据,有望解决电互联在带宽和功耗上面临的瓶颈。
- 神经拟态计算: 模拟生物神经网络结构和脉冲信号传递,探索超低功耗的事件驱动型AI计算。
- 量子计算探索: 虽然实用化尚早,但量子计算在处理特定优化、模拟问题上具有潜在优势,可能在未来开辟全新的AI范式。
AI模型与硬件的关系是相互成就的共生体,模型的演进驱动硬件架构的革新,而每一次硬件的突破又为更强大、更复杂的AI模型打开了大门,从云端的超算集群到手中的智能手机,从自动驾驶汽车到工厂的智能质检,正是这种深度的软硬协同,让AI从实验室的构想,真正转化为改变生产力和日常生活的现实力量,理解这种结合的内在逻辑,才能把握人工智能发展的核心驱动力,随着量子计算、光子芯片等前沿技术的探索,硬件对智能边界的拓展仍充满无限可能。
本文参考了包括MLPerf基准测试组织、IEEE Spectrum期刊以及主要芯片制造商(NVIDIA、Intel、Google TPU团队)发布的技术白皮书与架构解析资料。

 13888888888
13888888888

 点击咨询
点击咨询 