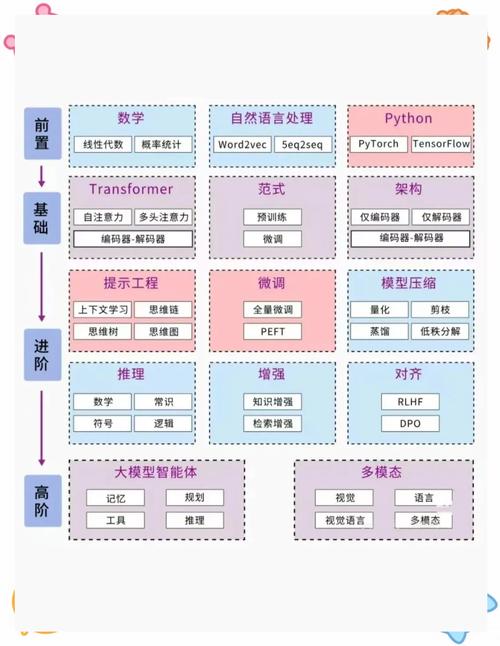
AI模型库导入模型实战指南:解锁智能应用的关键一步
当你的AI项目需要新能力时,导入预训练模型到模型库是最快捷的途径,这个过程看似简单,却直接影响后续开发效率与模型表现,本文将一步步拆解模型导入流程,助你高效驾驭AI模型库。
导入前的必要准备:奠定成功基础
- 精准定位模型源: 明确从哪里获取模型,主流来源包括:
- 官方模型库: Hugging Face Hub、PyTorch Hub、TensorFlow Hub等平台提供海量经过验证的模型。
- 开源社区: GitHub上的热门项目常包含优秀模型及权重。
- 自定义训练: 自主训练完成的模型文件(
.pt,.h5,.ckpt等)。
- 模型格式确认: 模型格式是导入的核心钥匙,常见格式有:
- PyTorch:
.pt或.pth(通常包含模型架构与权重状态字典)。 - TensorFlow/Keras: SavedModel 目录、
.h5文件、或冻结图.pb文件。 - ONNX:
.onnx(跨框架通用格式,需模型库支持)。 - TensorFlow Lite:
.tflite(移动/嵌入式设备常用)。
- PyTorch:
- 环境一致性检查: 确保目标模型库的运行环境(框架版本如PyTorch、TensorFlow;依赖库)与模型训练环境兼容,版本差异常导致加载失败。
- 模型文档精读: 仔细查阅模型文档,了解其输入输出格式、预处理要求、特定依赖项,文档是避免“踩坑”的路线图。
核心导入流程详解:步步为营
获取模型文件:
- 从平台下载:在Hugging Face Hub等平台,找到模型页面,通常有明确的下载按钮或代码片段(如
pip install transformers+from_pretrained)。 - 本地准备:将自主训练或从其他途径获得的模型文件(
.pt,.h5, SavedModel文件夹等)放置在项目目录或指定路径。
- 从平台下载:在Hugging Face Hub等平台,找到模型页面,通常有明确的下载按钮或代码片段(如
选择正确的加载方法(核心步骤):
PyTorch (
torch):import torch # 方式1:加载整个模型 (包含架构和权重) model = torch.load('path/to/model.pth') model.eval() # 切换到评估模式 # 方式2:加载权重到已定义的模型架构 (更灵活、常用) from my_model import MyModelClass model = MyModelClass(*args, **kwargs) # 实例化你的模型类 state_dict = torch.load('path/to/weights_only.pth') model.load_state_dict(state_dict) model.eval()TensorFlow/Keras:
import tensorflow as tf # 方式1:加载 SavedModel model = tf.saved_model.load('path/to/saved_model_dir') # 或使用 tf.keras.models.load_model (适用于 Keras SavedModel/ .h5) model = tf.keras.models.load_model('path/to/model.h5') # 方式2:仅加载权重 (需先创建相同架构模型) model = MyKerasModel(*args, **kwargs) # 实例化你的模型类 model.load_weights('path/to/weights.h5')Hugging Face Transformers (推荐): 极大简化了NLP模型的加载:
from transformers import AutoModelForSequenceClassification, AutoTokenizer model_name = "bert-base-uncased" # 或你在Hub上找到的模型ID model = AutoModelForSequenceClassification.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name)
ONNX Runtime: 加载用于推理的ONNX模型:
import onnxruntime as ort session = ort.InferenceSession('path/to/model.onnx') # 使用 session.run([output_name], {input_name: input_data}) 进行推理
模型验证与集成:
- 输入输出测试: 用一个小样本数据测试模型是否能正确运行,输出是否符合预期格式和范围。
- 预处理/后处理对接: 确保模型所需的预处理(如图像归一化、文本分词)和后处理步骤已正确集成到你的应用流程中。
- 封装集成: 将加载好的模型封装成服务接口、推理函数或集成到更大的应用框架中。
典型挑战与解决之道
- 报错:版本不兼容 (
UnpicklingError,AttributeError):- 尝试在匹配原始训练环境(框架及主要库版本)中加载。
- 使用ONNX格式转换进行跨版本/跨框架部署。
- 检查模型文档或社区,看是否有特定版本要求。
- 报错:模型架构不匹配 (
KeyError, 层名不匹配):- 使用“加载权重到已定义架构”方式时,确保本地定义的模型类与保存权重的模型结构完全一致。
- 仔细核对层名,使用
print(model.state_dict().keys())(PyTorch) 或model.summary()(Keras) 对比差异。
- 报错:未知格式或文件损坏:
- 重新下载模型文件,验证下载完整性(如校验MD5/SHA)。
- 确认文件格式是否被模型库支持。
- 性能不佳或资源不足 (OOM - Out of Memory):
- 检查模型大小是否超出可用内存(GPU/CPU RAM)。
- 考虑模型量化(降低数值精度,如FP32 -> FP16/INT8)、剪枝或选择更小的模型变体。
- 优化批次大小(Batch Size)。
模型导入的价值与最佳实践
高效导入模型是AI应用落地的起点,它不仅节省了宝贵的训练时间和计算成本,更能直接利用社区顶尖的研究成果,想象一下,一个医疗团队通过导入最新的病灶检测模型,快速提升了影像分析系统的准确率;或者金融风控系统接入优化的欺诈识别模型,显著降低了风险,这些正是模型导入带来的直接价值。
保持模型库的清晰管理和文档记录至关重要,建立命名规范,详细记录每个导入模型的来源、版本、用途、性能指标和测试结果,定期更新模型,关注社区动态和官方发布的新版本或优化版本,确保你的应用始终具备竞争力,技术迭代的速度从未如此迅猛,唯有持续学习与实践,方能在AI浪潮中稳健前行,每一次成功的模型导入,都是向智能化目标迈出的坚实一步。

 13888888888
13888888888

 点击咨询
点击咨询 