人工智能大模型的搭建是一个复杂而系统的过程,涉及多个关键环节,随着技术发展,越来越多的研究者和企业开始探索如何构建高效可靠的模型,本文将逐步介绍搭建AI大模型的基本方法,帮助读者理解其核心原理。
数据收集与预处理
搭建AI大模型的第一步是数据收集,模型需要海量高质量文本数据来学习语言模式,常见的数据来源包括公开语料库、网络文档和书籍,数据必须经过清洗,去除重复、无关或低质量内容,并进行分词、标注等预处理,这一环节对模型性能至关重要,因为垃圾数据会导致模型输出不准确。
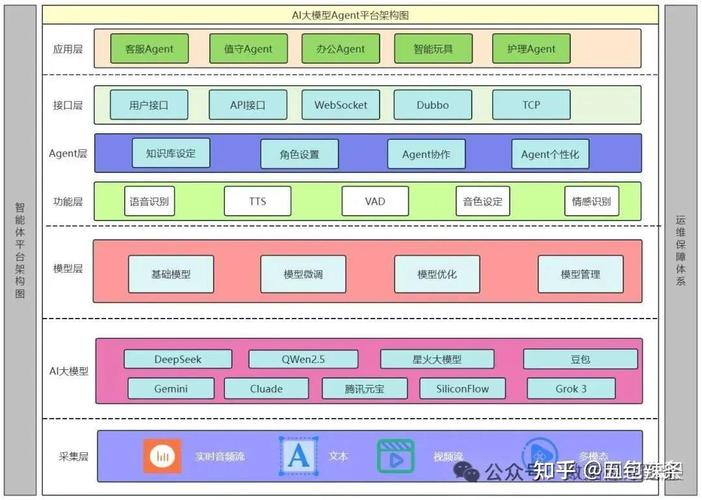
模型架构选择
选择合适的模型架构是核心步骤,当前主流架构基于Transformer,它通过自注意力机制处理序列数据,能有效捕捉长距离依赖关系,GPT系列模型采用解码器结构,而BERT使用编码器,架构设计需考虑参数规模、层数和注意力头数,参数越多,模型能力越强,但训练成本也更高,团队会根据资源和应用场景调整架构细节。
训练过程详解
训练阶段需要大量计算资源,通常使用GPU或TPU集群,过程分为预训练和微调两步,预训练时,模型在无标注数据上学习通用语言表示,通过预测下一个词或掩码词来优化参数,微调则针对特定任务,使用标注数据调整模型,优化算法如AdamW和学习率调度能加速收敛,训练中需监控损失函数,防止过拟合,并定期保存检查点。
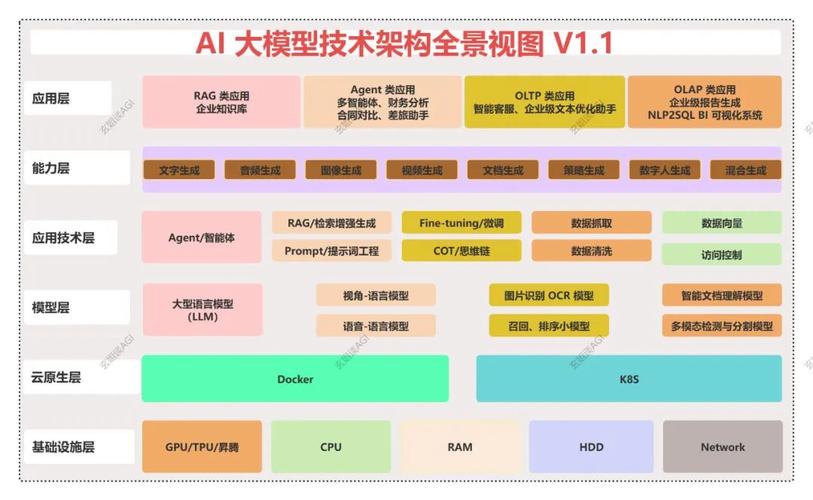
评估与优化方法
模型训练完成后,需进行严格评估,常用指标包括困惑度、准确率和F1分数,基准测试如GLUE或SuperGLUE能全面衡量模型性能,优化手段包括剪枝、量化和知识蒸馏,以降低模型大小和推理延迟,伦理评估不可忽视,需测试模型偏见和安全性,确保输出符合社会规范。
部署与维护
部署阶段将模型集成到应用中,涉及API设计、负载平衡和监控,云服务平台可简化此过程,维护包括定期更新数据、重新训练模型以应对分布漂移,并收集用户反馈进行迭代改进。

从个人角度看,AI大模型的搭建不仅是技术挑战,更体现了人类对智能系统的探索,随着算法进步和硬件升级,模型将更高效、易用,但我们也需关注资源公平性和伦理边界,确保技术服务于社会福祉。

 13888888888
13888888888

 点击咨询
点击咨询 