华为开源AI模型:开发者触手可及的人工智能力量
华为投身开源社区,为全球开发者贡献了多款强大的AI模型与框架,显著降低了人工智能的应用门槛,这些资源不再是实验室的专属,而是每一位技术探索者都能驾驭的工具,下面我们深入解析如何将这些模型融入你的项目。
华为开源AI的核心资源
- 盘古 (PanGu) 系列大模型: 涵盖自然语言处理(如盘古α)、计算机视觉(盘古·视觉)、科学计算等多个领域的超大规模预训练模型,提供强大的通用能力。
- MindSpore 全场景AI框架: 华为自研的开源深度学习框架,支持端、边、云全场景部署,以开发友好、高效运行、安全可信著称,其ModelZoo汇集了大量预训练模型。
- 昇腾 (Ascend) AI 处理器支持: 开源模型通常深度优化,可在华为昇腾芯片上获得最佳性能,同时也支持GPU等硬件。
实战指南:使用华为开源AI模型
明确需求与选型:
- 任务定义: 清晰你的目标——是文本生成、图像识别、语音处理还是科学预测?
- 模型探索: 访问官方资源是关键:
- 华为开源主页:
https://www.huaweicloud.com/ascend/developer(Ascend开发者) - MindSpore 官网:
https://www.mindspore.cn/(查看教程、文档和ModelZoo) - 华为云ModelArts 模型市场:
https://console.huaweicloud.com/modelarts/(部分模型提供) - 代码托管平台: GitHub/Gitee 搜索 “Huawei”, “MindSpore”, “PanGu”。
- 华为开源主页:
- 匹配模型: 根据任务复杂度、数据规模、硬件条件选择最合适的预训练模型,中文文本生成可考虑盘古α,图像分类可查看MindSpore ModelZoo中的ResNet变种。
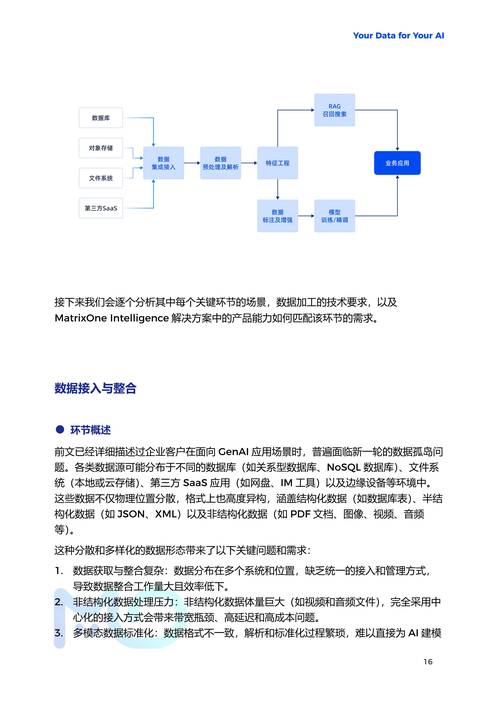
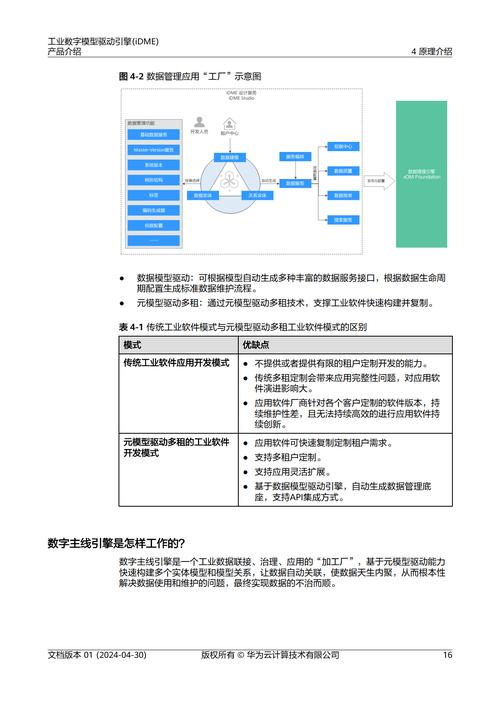
搭建运行环境:
- 基础依赖: 安装Python(推荐3.7+)及科学计算库(如NumPy)。
- 深度学习框架: 绝大多数华为模型基于 MindSpore,通过pip安装:
pip install mindspore注意:根据你的硬件(Ascend NPU, GPU, CPU)选择对应的版本(如
mindspore-ascend),并严格参照官方安装指南配置环境(尤其是昇腾环境)。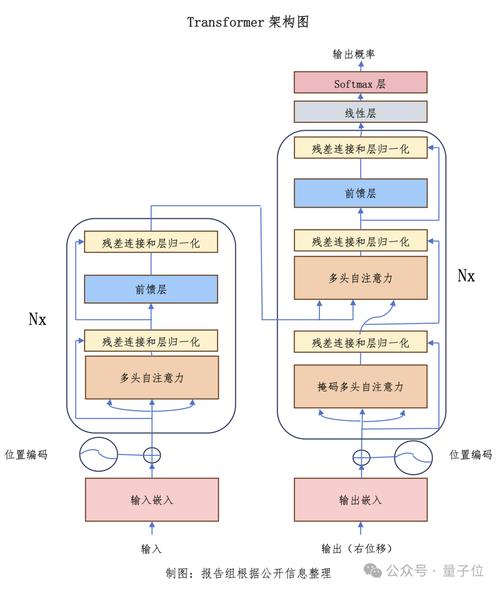
- 其他依赖: 安装模型所需的特定库,如
transformers(用于盘古等NLP模型)、opencv-python(视觉任务)等。
获取模型与加载:
- 官方下载: 从MindSpore ModelZoo、华为云ModelArts或项目GitHub/Gitee仓库获取模型文件(通常是
.ckpt或.mindir格式)和配套代码。 - Hugging Face Hub (部分模型): 如盘古α等模型也可能托管在Hugging Face平台,可通过
transformers库加载:from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("huawei-noah/pangu-alpha") model = AutoModel.from_pretrained("huawei-noah/pangu-alpha") - MindSpore 加载: 对于ModelZoo模型,通常有配套的加载脚本:
from model_zoo.official.cv.resnet import resnet50 net = resnet50(pretrained=True) # 加载预训练权重
- 官方下载: 从MindSpore ModelZoo、华为云ModelArts或项目GitHub/Gitee仓库获取模型文件(通常是
数据处理与输入:
- 根据模型要求,对原始数据进行预处理(如图像缩放归一化、文本分词)。
- 使用模型对应的
tokenizer(NLP)或数据处理脚本将数据转换为模型可接受的张量格式。 - 构建数据加载管道(可使用MindSpore的
Dataset和DataLoader模块)。
模型推理与应用:
- 直接推理: 加载预训练模型后,输入处理好的数据即可得到预测结果(分类、生成文本、检测框等)。
# 伪代码示例 (以MindSpore为例) input_data = ... # 处理好的输入数据 output = net(input_data) # 前向传播,得到输出
- Fine-tuning (微调 - 更常见): 如果预训练模型不完全匹配你的特定任务或数据,需要在其基础上进行微调:
- 准备你的标注数据集。
- 修改模型输出层(如调整分类数)。
- 定义损失函数和优化器。
- 在MindSpore中构建训练循环,加载预训练权重,在你的数据上训练若干轮次。 微调能显著提升模型在特定领域的性能。
- 直接推理: 加载预训练模型后,输入处理好的数据即可得到预测结果(分类、生成文本、检测框等)。
部署与集成:
- 云部署: 将训练/微调好的模型部署到华为云ModelArts等服务,提供API接口。
- 端侧部署: 使用MindSpore Lite将模型转换为轻量级格式,部署到手机、IoT设备(需昇腾芯片或兼容硬件)。
- 应用集成: 将模型推理能力集成到你的Web应用、移动App或业务系统中。
拥抱机遇,明晰挑战
显著优势:
- 技术高起点: 直接利用华为前沿研究成果,省去从零训练的巨大成本。
- 强大性能: 尤其在昇腾硬件上,优化模型展现出卓越的效率。
- 活跃社区: 开源社区提供持续更新、问题讨论和案例分享。
- 全栈支持: MindSpore框架 + 昇腾硬件 + 开源模型,形成完整生态。
注意事项:
- 学习曲线: MindSpore框架有其独特设计,需投入时间学习(但文档丰富)。
- 环境配置: 昇腾环境配置相对复杂,需仔细阅读官方文档,GPU/CPU版更易上手。
- 模型理解: 有效使用(尤其微调)需理解模型架构和任务特性。
- 算力需求: 大模型(如盘古)训练/推理对算力要求极高,云端资源常是必要选择。
- 合规与许可: 严格遵守所选模型的开源协议(如Apache 2.0, GPL等),特别注意模型权重分发的条款。商业应用前务必进行法律合规评估。
个人观点
华为将尖端AI模型开源,其价值远超代码本身,它代表了一种开放协作、推动普惠AI的坚定态度,对于开发者而言,这如同获得了一个功能强大的工具箱,初探时,环境配置或框架差异可能带来短暂困扰,但华为详实的文档和活跃的社区是坚实后盾,选择适合当前技能和资源的模型入手(不必强求最大最复杂的盘古),从ModelZoo的一个CV小模型实践推理和微调,成功后再挑战更复杂场景,关键在于动手实践——克隆代码、配置环境、跑通第一个Demo,模型开源只是起点,真正的价值在于开发者如何将它们应用于解决实际问题、激发创新,华为提供的是引擎,而驾驶它驶向何方,创造何种价值,完全取决于开发者的想象力与执行力,每一次成功的应用集成,都是对这场开源行动最好的回应,技术浪潮中,开放者得先机。
关键提示: 开源项目迭代迅速,务必以华为MindSpore官网、昇腾开发者社区及具体模型项目仓库的最新文档和公告为准,模型的具体使用细节、API接口、依赖版本等信息请严格参照对应项目官方说明。

 13888888888
13888888888

 点击咨询
点击咨询 