在数字化浪潮席卷各行各业的今天,人工智能(AI)已不再是遥不可及的未来科技,而是触手可及的生产力工具,特别是开源联网AI模型的兴起,极大地降低了技术门槛,让个人开发者、中小型企业乃至普通爱好者都能以极低的成本,构建出功能强大、反应智能的应用,本文将深入探讨如何有效利用这些开放的AI资源,并融入联网能力,释放其真正的潜能。
理解开源联网AI模型的核心
开源AI模型,顾名思义,是源代码开放、允许任何人自由使用、修改和分发的AI模型,它们通常由顶尖科技公司、研究机构或活跃的社区开发并维护,例如Meta的Llama系列、Mistral的模型以及众多在Hugging Face等平台上发布的优秀模型。“联网”能力则是为其锦上添花的关键,一个原本只能基于训练数据静态应答的模型,通过接入互联网搜索API或内部知识库,就能实时获取最新信息,回答关于时事、股价、新闻等动态问题,其准确性和实用性因此得到质的飞跃。
如何开始使用:一份实践指南
使用这类模型并非想象中复杂,其过程可以概括为几个核心步骤。
选择适合的模型,这是所有工作的起点,你需要根据自身需求(是文本生成、代码编写还是多模态交互?)、硬件资源(是否有强大的GPU?)和技术能力来选择,对于初学者,可以从参数量较小、社区支持活跃的模型开始,例如Gemma或Llama 3的较小参数版本,Hugging Face平台是发现和筛选模型的绝佳起点。
配置运行环境,获得模型权重后,你需要一个能够运行它的环境,最常见的方式是使用Python,并依托于诸如Transformers、Torch等深度学习库,对于本地部署,你需要确保计算机拥有足够的存储空间来容纳模型文件(从几GB到上百GB不等),并且如果希望获得流畅的生成体验,一块性能足够的NVIDIA显卡几乎是必需品,如果硬件条件有限,完全可以利用Google Colab、RunPod等云服务来租用所需的算力,这是一种非常灵活且成本可控的方案。
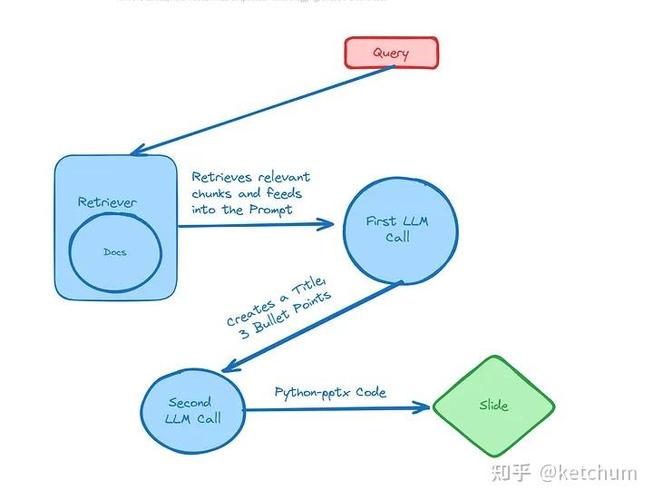
第三,为其注入“联网”能力,这是让模型变得“聪明”的关键一步,核心思路是为AI模型安装一个“外部信息查询插件”,在技术实现上,这通常意味着:
- 构建一个信息检索接口:当模型接收到用户 query(查询)时,首先由一个判断机制决定是否需要联网查询,当问题涉及“今天北京的天气”或“某公司的最新财报”时,触发联网搜索。
- 调用搜索API:程序会自动调用如Serper API、SerpAPI或Bing Search API等付费或免费的搜索引擎接口,获取最新的搜索结果摘要或链接。
- 信息整合与应答:将搜索返回的实时信息作为新增的上下文(Context),与用户的原始问题一并提交给本地运行的开源大模型,模型会基于这些最新的、确凿的证据来组织语言,生成最终答案,从而避免因训练数据陈旧而产生的幻觉或错误。
优势与挑战并存
采用开源联网方案的优势显而易见:极高的可控性和隐私性,所有数据和处理过程都可以留在本地或私有服务器上,特别适合处理敏感信息;强大的定制自由度,你可以针对特定行业或领域对模型进行微调(Fine-tuning),让它成为某个垂直领域的专家;以及显著的成本优势,避免了长期依赖闭源商业API所带来的高昂费用。
挑战也不容忽视。技术门槛是首要问题,需要具备一定的机器学习运维(MLOps)和软件开发能力。硬件成本虽然长远来看更划算,但前期仍需投入。效果优化是一个持续的过程,你需要不断调试提示词(Prompt Engineering)、优化检索逻辑,才能得到最稳定、最可靠的结果。
展望未来
开源联网AI模型正在推动一场深刻的AI民主化运动,它使得技术的所有权从少数巨头手中分散到广大开发者群体里,激发了无穷的创新活力,随着模型效率的不断提升和部署工具的日益简化,它的应用边界将持续扩大,对于每一位有志于探索AI世界的实践者来说,现在正是亲手搭建、实验并创造的最佳时机,拥抱开源,善用联网,你便能将全球最前沿的AI智慧,转化为驱动自身业务与创新的强大引擎。

 13888888888
13888888888

 点击咨询
点击咨询 