如何训练专有的AI模型:释放数据价值的核心路径
在人工智能浪潮席卷全球的当下,拥有一个专属于自身业务或领域的AI模型,已不再是科技巨头的专利,它正成为企业提升效率、优化决策、创造独特用户体验的核心驱动力,掌握训练专有AI模型的能力,意味着掌握了一把开启未来竞争力的钥匙。
基石:高质量数据的获取与锤炼
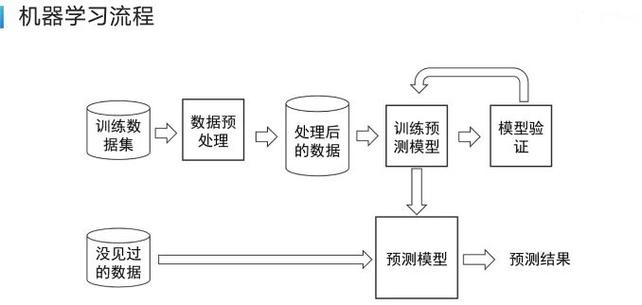
训练一个强大专有模型的第一步,也是最关键的一步,是构建高质量的数据集,这远非简单的数据堆砌。
- 精准定义需求: 明确模型要解决的具体问题至关重要,是用于图像识别、智能客服、销售预测还是风险评估?清晰的目标决定所需数据的类型、结构和规模。
- 数据的收集与清洗: 从内部业务系统、用户交互日志、专业数据库或经授权的第三方渠道获取原始数据,数据清洗环节必不可少,需剔除无效信息、修正错误格式、处理缺失值,确保数据的一致性与准确性。
- 专业的标注与增强: 对于监督学习任务(如图像分类、语义理解),数据标注的质量直接影响模型性能,需投入资源进行专业化、标准化的标注工作,并建立严格的质量控制流程,数据增强技术(如图像翻转、裁剪、添加噪声,文本的同义词替换、句式改写)能有效扩充数据集规模,提升模型泛化能力。
- 安全与合规: 处理数据,尤其涉及用户隐私或商业机密的信息时,必须严格遵守相关法规(如GDPR、个人信息保护法),采用脱敏、加密技术保护数据安全是基本要求。
骨架:模型架构的明智选择

面对众多开源模型架构,选择或设计最适合任务的模型是成功的关键。
- 预训练模型微调: 对于绝大多数场景,这是最高效的起点,利用在大规模通用数据集(如ImageNet、Wikipedia文本)上预训练好的强大模型(如BERT、GPT系列、ResNet、ViT),在其基础上,使用专有数据集进行微调,这能极大节省训练时间和计算资源,同时继承模型在通用特征提取上的强大能力,Hugging Face、TensorFlow Hub、PyTorch Hub等平台提供了丰富的预训练模型资源。
- 从零开始训练: 当任务极其独特,或预训练模型的基础架构完全不适用时(如特殊传感器数据处理、全新模态任务),才考虑从头训练,这需要海量高质量数据和强大的计算资源支撑。
- 领域模型适配: 某些领域(如生物医药、法律、金融)已有针对该领域数据特点优化的预训练模型(如BioBERT、FinBERT),直接采用或在其基础上微调效果更佳。
- 计算资源考量: 模型复杂度(层数、参数量)需与可用的GPU/TPU计算资源、训练时间预算相匹配,复杂的模型并非总是最佳选择。
锻造:模型训练的精雕细琢

选好模型架构,准备好高质量数据,真正的“锻造”过程开始。
- 环境搭建: 强大的硬件是基础,GPU(如NVIDIA Tesla系列)或更专业的TPU是加速深度学习训练的标配,云计算平台(AWS SageMaker, Google AI Platform, Azure ML)提供了灵活、可扩展的训练环境,降低了本地基础设施投入门槛。
- 框架选择: TensorFlow、PyTorch是目前最主流的深度学习框架,拥有庞大的社区和丰富的工具库支持,Keras作为TensorFlow的高级API,简化了模型构建过程。
- 训练过程:
- 数据切分: 将数据集划分为训练集(用于模型学习)、验证集(用于在训练过程中评估模型表现、调整超参数、防止过拟合)和测试集(用于最终评估模型泛化能力),常用比例如70%-15%-15%。
- 损失函数与优化器: 根据任务类型(分类、回归、生成等)选择合适的损失函数(如交叉熵、均方误差),优化器(如Adam、SGD)负责在训练过程中调整模型参数以最小化损失。
- 超参数调优: 学习率、批次大小、训练轮数(Epochs)、正则化强度等超参数对模型性能影响巨大,需通过实验,结合验证集反馈进行精细调整,自动化超参数优化工具(如Optuna, Ray Tune)能提升效率。
- 监控与调试: 使用TensorBoard、Weights & Biases等工具实时监控训练过程中的损失、准确率等关键指标变化,及时发现过拟合、欠拟合等问题并进行调整(如早停策略Early Stopping)。
检验:性能评估与持续迭代
训练完成的模型需接受严格评估,并非一劳永逸。
- 核心指标: 在独立的测试集上评估模型性能,常用指标包括准确率、精确率、召回率、F1值、AUC-ROC(分类任务),均方误差、平均绝对误差(回归任务),BLEU、ROUGE(生成任务)等。
- 业务指标对齐: 技术指标达标只是第一步,模型最终价值体现在解决实际业务问题上,需评估模型上线后对关键业务指标(如转化率、用户满意度、成本节约、风险降低)的实际提升效果。
- 鲁棒性与公平性: 测试模型在不同数据分布、噪声干扰、对抗攻击下的表现(鲁棒性),检查模型预测是否存在对不同群体的偏见(公平性),这对构建负责任的人工智能至关重要。
- 持续优化: AI模型是“活”的系统,随着业务发展、数据分布变化(数据漂移),模型性能会下降,建立持续监控机制,定期用新数据重新训练或微调模型,是保持其长期有效性的关键。
应用:模型部署与价值释放
训练评估合格的模型需要有效部署才能产生实际价值。
- 部署方式: 根据需求选择在线API服务(实时响应请求)、边缘端部署(低延迟、离线可用)或批量预测(处理海量离线数据)。
- 模型优化: 为满足部署环境(如移动端、嵌入式设备)的资源限制(计算力、内存、功耗),常需对模型进行压缩和加速,常用技术包括量化(降低数值精度)、剪枝(移除冗余参数)、知识蒸馏(小模型学习大模型知识)等。
- 监控与反馈闭环: 在生产环境中持续监控模型的预测性能、延迟、资源消耗等指标,收集用户反馈和预测结果数据,形成闭环,用于模型的进一步迭代优化。
个人观点
训练专有AI模型,绝非追逐技术时髦的简单尝试,而是企业构建核心数字资产的战略投资,其核心价值在于将独特的数据资源转化为不可替代的智能优势,这个过程充满挑战——数据质量的门槛、算力成本的考量、专业人才的稀缺、模型优化的复杂性都是切实存在的障碍,清晰的业务目标定位、对数据治理的长期投入、以及拥抱开源生态和云计算的灵活性,能够显著降低门槛,成功的专有模型不仅带来效率提升和成本节约,更能解锁全新的产品形态、服务模式和用户体验,成为企业在智能化竞争中脱颖而出的关键壁垒,数据是新时代的“石油”,而专有AI模型则是将其提炼为高价值产品的核心“炼油厂”。

 13888888888
13888888888

 点击咨询
点击咨询 