盘古AI模型使用教程:释放国产大模型的强大能力
盘古AI模型作为华为推出的国产大语言模型代表,以其强大的通用能力和在中文语境下的优异表现,吸引了众多用户和企业关注,掌握其使用方法,能极大提升工作效率与创造力,本教程将详细讲解盘古AI模型的使用步骤与核心技巧。
获取访问权限:开启盘古之旅 目前盘古AI模型主要通过华为云平台提供服务,首要步骤是注册并完成华为云账号的实名认证,登录华为云官网,在顶部导航栏找到“产品”或“服务”,进入人工智能领域,搜索“盘古大模型”,根据您的需求(如自然语言处理、代码生成、多模态等),选择合适的盘古子模型服务(盘古 NLP 大模型),部分服务可能需要开通或申请,请留意官方说明,账号安全是使用基础,务必设置强密码并开启二次验证。
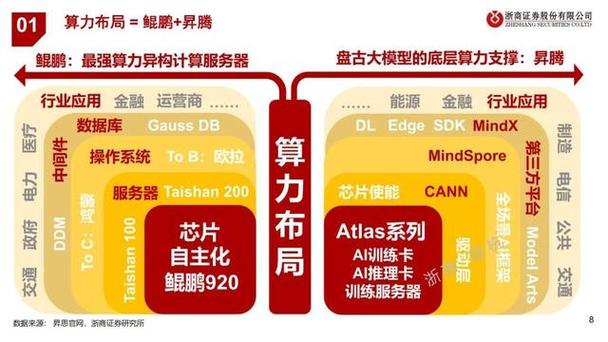
核心使用方式:API接入与在线体验
API调用(开发者/企业首选):
- 创建项目与凭证: 在华为云控制台,进入“AI开发平台 ModelArts”或相关服务控制台,创建新项目,获取API调用的认证密钥(如AK/SK)。
- 查阅API文档: 仔细阅读盘古模型对应服务的API文档,了解接口地址、请求参数(必填:模型名称、输入文本/指令;可选:生成长度、温度值、Top_p值等)、请求格式(通常为JSON)和返回结果格式。
- 编写调用代码: 使用您熟悉的编程语言(Python、Java等),通过HTTP请求库(如requests)向API端点发送POST请求,携带认证信息和参数,示例(Python伪代码):
import requests url = "https://{endpoint}/v1/{project_id}/nlp/foundation-models" # 替换为实际端点 headers = { "Content-Type": "application/json", "X-Auth-Token": "{your_token}" # 或使用AK/SK方式认证 } data = { "model_id": "pangu-base", # 指定盘古模型ID "input": "写一篇关于人工智能发展趋势的短文,500字左右。", "parameters": { "max_new_tokens": 500, "temperature": 0.7 } } response = requests.post(url, headers=headers, json=data) result = response.json() print(result["result"]["output_text"]) # 输出模型生成内容 - 调试与集成: 在本地或测试环境调试代码,确保调用成功并正确处理返回结果,再集成到您的应用系统中。
在线体验与测试(快速上手): 华为云常会提供盘古模型的在线演示或沙箱环境(如在 ModelArts 的 AI Gallery 中寻找相关模型资产),用户可通过网页界面直接输入问题或指令,实时查看模型生成效果,这非常适合初学者理解模型能力边界和测试提示词(Prompt)效果,无需编写代码。
掌握交互核心:高效Prompt编写 盘古模型的能力发挥极大依赖于用户输入的指令(Prompt),优质Prompt能显著提升输出质量:
- 清晰明确: 直接说明任务目标,避免模糊表述。
- 模糊:“说说科技”。
- 清晰:“概述近三年人工智能在医疗影像诊断领域的主要突破,列出三项关键技术并简要说明其优势。”
- 提供上下文: 当任务复杂时,给予必要背景信息。“我正在撰写一份关于新能源汽车电池技术的市场报告,目标读者是行业投资者,请分析当前主流三元锂电池和磷酸铁锂电池的成本结构差异及未来三年降本趋势预测。”
- 指定格式与长度: 明确要求输出结构。“请生成一个关于‘时间管理’的5点建议清单,每点建议用一句话概括,再附上1-2句解释说明。” 或 “请用300字以内,以新闻报道的口吻,描述本次合作签约的意义。”
- 分步引导(复杂任务): 对于需要多步推理或创作的任务,可尝试将问题拆解。“第一步,分析用户评论:‘这款手机拍照很好,但电池一天都撑不住。’ 识别核心观点(优点和缺点),第二步,根据识别的观点,生成一条礼貌、专业的客服回复,表示理解并承诺反馈改进。”
- 善用示例(Few-shot Learning): 在Prompt中提供1-2个输入输出示例,能有效引导模型理解您的期望格式和风格。
进阶技巧:参数调优与文件处理
关键参数调整:
- Temperature (温度): 控制生成文本的随机性(0.0-1.0+),值越低(如0.2),输出越确定、保守、重复;值越高(如0.8),输出越多样、有创意,但可能偏离主题,报告、摘要等任务宜用低温;创意写作可用高温。
- Max New Tokens / Max Length (最大生成长度): 限制模型生成内容的最大长度(以token计,约等于字数),防止生成过长无关内容。
- Top-p (Nucleus Sampling): 控制采样词的范围(0.0-1.0),通常设置0.7-0.9,平衡质量与多样性,与Temperature配合使用。
- Repetition Penalty (重复惩罚): 降低重复词出现的概率,值大于1.0(如1.2)可有效减少重复。
处理: 盘古模型支持通过API上传文本文件(如TXT、PDF、Word、Excel等,需确认具体模型支持格式),提取其中文字信息进行处理。
- 长文档摘要: 上传报告文件,指令:“请提炼这份市场研究报告的核心观点和关键数据结论,形成一份500字以内的执行摘要。”
- 合同关键信息提取: 上传合同PDF,指令:“请提取本合同中的甲方名称、乙方名称、合同金额、付款方式、主要交付物和合同有效期。”
- 表格数据问答: 上传包含数据的Excel文件,指令:“根据附件表格中2023年Q1-Q4各区域的销售数据,计算华东地区的全年销售总额和季度平均销售额,并指出销售额最高的季度。”
- 多轮对话结合文件: 先上传文件,后续对话可基于文件内容提问:“刚才上传的会议纪要中,关于项目上线时间是如何决定的?”
应用场景实例
- 内容创作: 自动生成营销文案、社交媒体帖子、新闻稿、小说章节、诗歌、视频脚本。
- 办公提效: 撰写/润色邮件、报告、PPT大纲;会议纪要整理与摘要;合同/文档关键信息提取与审核。
- 代码辅助: 根据注释生成代码片段;解释复杂代码逻辑;调试建议;不同编程语言间转换。
- 知识问答与研究: 快速获取领域知识解释;整理文献要点;生成研究思路或提纲。
- 客户服务: 自动生成常见问题回复草稿;分析用户评论/反馈情感与要点;构建智能客服知识库。
- 数据处理与分析: 理解并生成SQL查询;解释数据报告;将自然语言描述转换为数据处理步骤。
注意事项与最佳实践
- 数据安全: 严格遵守华为云服务协议,切勿通过API传输或上传包含个人隐私信息、国家秘密、商业核心机密等敏感数据,企业用户建议在私有环境部署或使用专属服务。
- 结果验证: 盘古模型虽强大,但生成内容仍需人工审核校验,特别是涉及事实、数据、法律、医疗等专业领域时,避免直接采信关键信息。
- 迭代优化: 首次输出不理想很正常,尝试调整Prompt表述、提供更多上下文、修改参数(如降低温度、增加生成长度限制)后重新生成,多轮对话往往能逼近最佳结果。
- 关注更新: 大模型迭代迅速,定期关注华为云官方公告和文档,了解盘古模型新版本、新功能(如多模态能力增强)或服务变更。
- 成本意识: API调用通常按Token计费,在开发调试阶段注意控制请求频率和生成长度,优化Prompt效率以减少无效请求。
盘古AI模型作为国产技术的标杆,其易用性与强大功能正不断拓展,无论是开发者集成创新应用,还是普通用户提升日常效率,掌握其核心使用方法都能带来显著收益,笔者认为,关键在于清晰的需求定义、有效的Prompt沟通以及必要的输出把关,善用工具而不依赖工具,方能最大程度释放AI潜能。
测试发现,将温度值设置在0.6-0.8区间,配合明确的格式要求(如"分三点说明,每点不超过20字"),能显著提升专业场景下的输出稳定性,当处理技术文档时,在提示词中加入"请用严谨的学术语言表述"这类风格指令,效果优于默认输出。

 13888888888
13888888888

 点击咨询
点击咨询 