在当今数字化时代,人工智能技术正迅速改变我们的生活和工作方式,开源AI模型作为这一领域的核心组成部分,为开发者和普通用户提供了强大的工具,让AI应用变得更加普及和可定制,许多人可能对开源AI模型感到陌生,但通过简单了解,任何人都能上手使用,本文将详细介绍开源AI模型的基本概念、使用方法和实际应用,帮助您快速入门。
开源AI模型指的是那些源代码公开、允许用户自由使用、修改和分发的AI模型,这些模型通常由社区或研究机构开发,涵盖了自然语言处理、图像识别、语音合成等多个领域,与闭源模型相比,开源模型具有更高的透明度和灵活性,用户可以根据需求进行调整,而无需依赖商业公司的限制。
使用开源AI模型的第一步是选择合适的模型,市场上常见的开源模型包括GPT系列、BERT、Stable Diffusion等,选择时,需要考虑模型的用途、性能要求和资源限制,如果您需要处理文本生成任务,GPT模型可能更适合;如果是图像生成,Stable Diffusion则是不错的选择,建议从官方文档或社区论坛获取最新信息,确保模型的可靠性和兼容性。
接下来是环境准备,大多数开源AI模型需要特定的运行环境,如Python编程语言和相关的库(例如TensorFlow或PyTorch),您可以在本地计算机或云服务器上搭建环境,对于初学者,推荐使用预配置的云平台,如Google Colab或Hugging Face,这些平台提供了免费的计算资源,简化了安装过程,安装完成后,下载模型文件,模型可以通过GitHub或专门的模型仓库获取,下载后解压到指定目录即可。
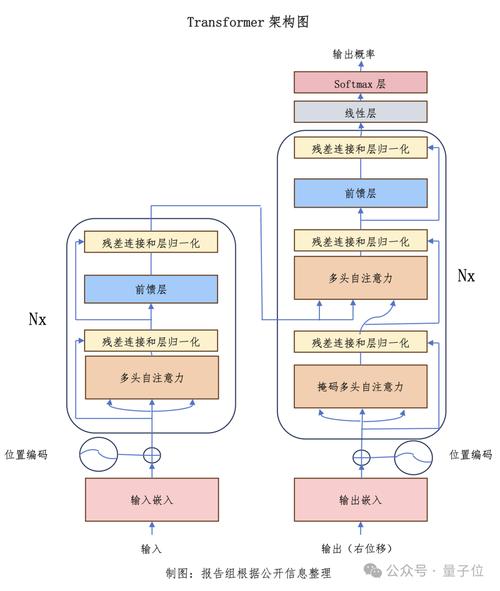
运行模型是核心步骤,以文本生成为例,使用GPT模型时,您需要编写简单的代码来加载模型并输入提示词,代码示例如下:首先导入必要的库,然后加载预训练模型,最后调用生成函数,这个过程可能涉及参数调整,如生成长度或温度设置,以控制输出的创造性,对于非技术用户,许多模型提供了图形界面工具,允许通过拖拽方式操作,无需编写代码。
微调是进阶用法,可以让模型适应特定任务,如果您想用AI模型生成行业报告,可以使用自己的数据集对模型进行微调,这需要准备标注数据,并运行训练脚本,微调过程可能耗时较长,但能显著提升模型在特定领域的表现,注意,微调需要一定的计算资源,建议从小型数据集开始尝试。
实际应用中,开源AI模型已广泛用于内容创作、客服系统、教育工具等领域,一位内容创作者可能使用开源模型自动生成文章草稿,节省时间;企业则可能部署模型来处理客户咨询,提高效率,这些应用不仅降低了技术门槛,还促进了创新。
在使用开源AI模型时,需注意一些常见问题,首先是版权和许可问题,确保模型的使用符合开源协议,其次是数据隐私,避免在处理敏感信息时泄露数据,模型可能存在的偏见或错误输出也需要人工审核,建议定期更新模型版本,以获取性能改进和安全修复。
从个人角度看,开源AI模型的普及代表了技术民主化的趋势,它让更多人能够接触和利用AI,而不必依赖大公司,随着社区贡献的增加,开源模型将变得更加强大和易用,我希望读者能通过实践,探索AI的无限可能,并将其应用于实际场景中,推动个人和社会的进步。

 13888888888
13888888888

 点击咨询
点击咨询 