解锁本地AI大模型部署:释放私有化智能的力量
在数据隐私日益受到重视、定制化需求激增的今天,将强大的人工智能大模型部署在本地环境,正成为企业、研究机构乃至个人开发者的关键战略,本地部署不仅意味着对核心数据与模型资产的完全掌控,更能实现深度定制与无缝集成,彻底摆脱云端服务的延迟与限制,如何迈出这关键一步?以下是部署本地AI大模型的完整路径。
第一步:精准评估——硬件与资源的基石 部署的起点在于清晰的自我认知,你需要深入评估:
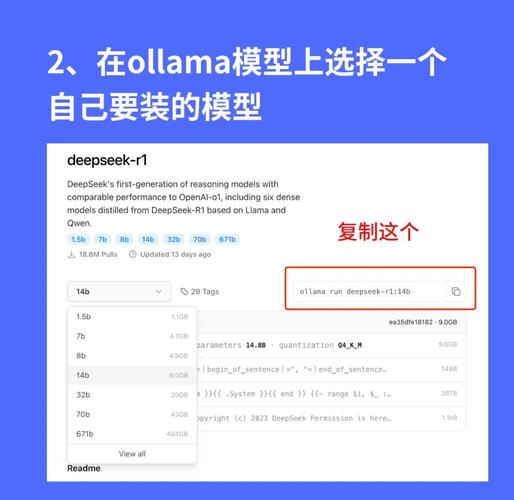
- 模型规模决定硬件需求: 计划运行的模型参数量(如7B、13B、70B)直接关联显存消耗,流畅运行Llama 3 70B模型通常需要双路专业级显卡(如RTX 6000 Ada 48GB)或服务器集群;而Llama 3 8B模型在单张高配消费卡(如RTX 4090 24GB)上即可胜任。
- 量化技术的魔力: 这是降低资源门槛的核心手段,利用GGUF/GGML等格式的量化模型(如4-bit、5-bit),能将原始模型压缩数倍,一个70B的FP16模型约需140GB显存,而经过4-bit量化后,仅需约35-40GB,使单卡或双卡部署成为可能。
- 内存与存储的支撑: 大模型加载与运算需要充足的系统内存(RAM),通常建议为模型量化后大小的1.5倍以上,高速NVMe固态硬盘(SSD)则能显著加速模型加载过程。
第二步:明智选择——模型与框架的匹配 面对开源生态的繁荣,选择需有的放矢:
- 明确任务目标: 是追求极致文本生成能力(如Llama 3、Mistral),强大的代码理解(如DeepSeek-Coder),还是多模态处理(如LLaVA)?目标驱动选型。
- 拥抱成熟开源生态: Hugging Face Hub是模型宝库,重点关注经过充分验证的模型家族(Llama、Mistral、Gemma、Qwen、DeepSeek等)及其社区衍生版本(如中文优化、指令微调模型)。
- 框架是运行引擎: 选择活跃且兼容性强的推理框架至关重要:
- LM Studio: 用户友好,适合个人快速体验,提供直观的图形界面。
- Ollama: 命令行为主,轻量高效,Mac/Linux体验优异,支持GGUF模型。
- text-generation-webui (oobabooga): 功能极其强大,支持多种后端(Transformers、llama.cpp、ExLlamaV2等),插件丰富(语音、图像),是搭建本地AI服务的瑞士军刀。
- vLLM: 专为高吞吐量、低延迟生产环境设计,尤其适合API服务部署。
第三步:构筑环境——依赖与工具的协同 稳定环境是高效运行的保障:
- Python为王: 确保安装合适版本的Python(推荐3.10或3.11),使用
venv或conda创建隔离的虚拟环境是避免依赖冲突的最佳实践。 - GPU加速核心: 安装与硬件匹配的CUDA工具包和cuDNN库,对于NVIDIA显卡,正确配置PyTorch的CUDA版本(如
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121)是解锁GPU算力的钥匙。 - 框架专属安装: 严格遵循所选框架(如text-generation-webui, Ollama)的官方文档进行安装和依赖项配置。
第四步:模型获取与准备——效率与精度的平衡
- 可信来源下载: 从Hugging Face Hub、模型官方仓库或信誉良好的社区镜像获取模型文件,优先选择包含GGUF量化版本的仓库(如TheBloke维护的模型)。
- 量化权衡: 根据硬件选择量化级别,4-bit或5-bit在精度损失与资源节省之间达到较佳平衡点(如
mistral-7b-instruct-v0.2.Q5_K_M.gguf),更高bit数(6-bit, 8-bit)精度更好但更耗资源;更低bit数(2-bit, 3-bit)资源占用少但可能显著影响效果。
第五步:启动与推理——从命令行到交互界面
- 命令行控制(以text-generation-webui为例):
- 激活虚拟环境。
- 启动Web UI:
python server.py --listen(使局域网可访问)。 - 在Model页面加载下载的模型文件(.gguf或原始PyTorch格式)。
- 切换至Text generation标签页即可开始对话或补全。
- Ollama的便捷: 若模型已被Ollama支持(如
ollama run llama3:8b),或可自行创建Modelfile定制模型,命令行交互简单直接。 - LM Studio的易用性: 在软件内搜索、下载模型(支持GGUF),直观界面中进行聊天或补全实验。
第六步:进阶优化与应用——释放全部潜能
- 参数调优: 在Web UI中调整
temperature(创造性)、top_p/top_k(输出多样性)、max_new_tokens(生成长度)等参数,精细控制模型行为。 - 打造API服务: 利用text-generation-webui的
--api启动参数或vLLM框架,将模型暴露为RESTful API,方便与现有应用(如CRM、知识库系统)集成。 - 构建智能体(Agent): 结合LangChain、LlamaIndex等框架,赋予模型使用工具(搜索、计算)、处理长文档、进行复杂推理和决策的能力。
- 长期对话记忆: 集成向量数据库(如ChromaDB, FAISS),通过嵌入模型存储和检索对话历史,实现真正的上下文感知。
- 视觉理解扩展: 部署多模态模型(LLaVA, Moondream),实现图像内容识别与分析。
部署本地大模型的价值远不止于技术实现本身。 它代表着对数据主权的捍卫——敏感信息无需离开安全边界;它开启了无限定制的可能——模型可以针对特定行业术语、内部流程进行深度优化,成为专属智能助手;它确保了服务的稳定与可控——摆脱网络波动与外部API限制,随着量化技术持续突破和硬件性能不断提升,曾经高不可攀的大模型能力,正变得触手可及,无论是开发者探索前沿技术,还是企业构建核心竞争力,掌握本地AI大模型的部署能力,无疑是掌控未来智能时代的关键一步,拥抱本地部署,就是拥抱真正自主、高效、安全的智能未来。

 13888888888
13888888888

 点击咨询
点击咨询 