在人工智能领域,模型部署并非一次性任务,而是一个持续优化的过程,迭代部署确保了AI系统在真实环境中保持高性能、适应变化并提升价值,作为网站站长,我经常处理这类挑战,理解其重要性:模型一旦上线,数据分布、用户需求或外部因素可能迅速变化,导致性能下降,迭代部署通过周期性更新模型版本,维持其可靠性和准确性,忽略这一过程,可能引发预测错误、用户流失或商业损失,掌握迭代方法对任何依赖AI的团队都至关重要。
为什么需要迭代部署?
AI模型部署后,初始版本基于训练数据构建,但现实世界充满不确定性,数据漂移——输入数据分布随时间变化——是常见问题,电商推荐模型在节假日期间可能失效,因为用户行为模式突变,概念漂移——目标变量定义改变——也需关注,如欺诈检测模型中,新攻击手法出现,模型本身可能有缺陷:过拟合导致泛化能力差,或训练偏差引发不公平结果,迭代部署允许团队响应这些动态,通过更新模型来弥补差距,这不仅提升用户体验,还强化系统韧性,在行业实践中,忽略迭代的公司常面临模型退化风险,而持续优化者则获得竞争优势。
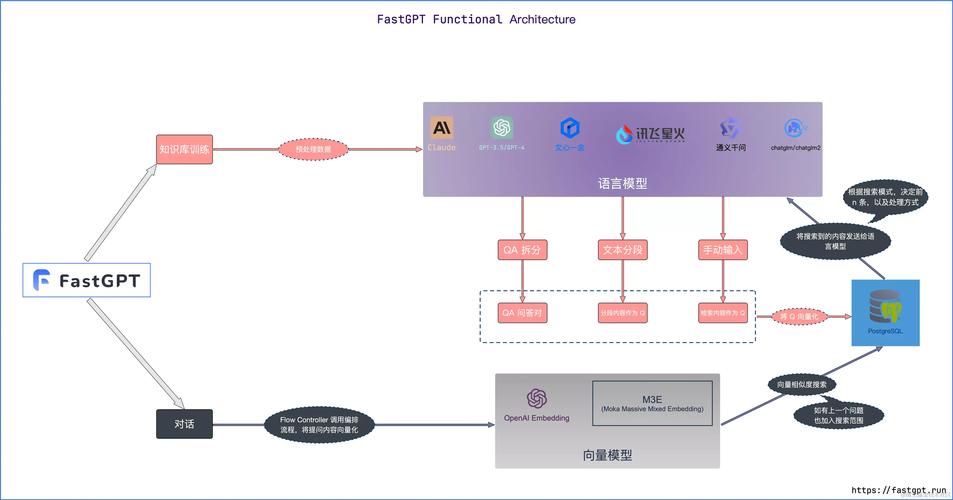
迭代部署的核心步骤
实施迭代过程需结构化方法,分为五个关键阶段,每个阶段依赖数据驱动决策,确保高效且低风险。
-
监控模型性能:部署后,实时跟踪指标是关键,使用工具如Prometheus或自定义仪表板监控精度、延迟、错误率,分类模型需关注F1分数和混淆矩阵;回归模型检查MAE(平均绝对误差),设置警报阈值,当指标偏离基线时触发行动,这一步是迭代基础,帮助识别问题根源,如数据异常或模型衰退。
-
收集反馈和数据:基于监控结果,主动获取新数据,这包括用户反馈、日志分析或A/B测试,A/B测试比较新旧模型版本,量化改进,收集近期生产数据用于再训练,避免过时样本,数据清洗和标注确保质量,减少噪声影响,此阶段强调闭环反馈,让迭代基于真实证据而非假设。
-
模型改进或重新训练:利用新数据更新模型,方法包括增量学习——在原有基础上微调参数,或全量再训练——从零开始构建,选择取决于变化规模:小调整用迁移学习,大变化则需重新训练,工具如TensorFlow或PyTorch简化流程,关键优化点:减少偏差、提升泛化或添加新特征,NLP模型迭代中,可能融入最新语言趋势以增强理解力。

-
测试新版本:在部署前,严格测试更新模型,单元测试验证代码逻辑;集成测试检查系统兼容性;性能测试评估负载处理,使用影子部署或金丝雀发布:先将新模型分流小部分流量,观察效果,若测试失败,回滚到旧版避免中断,测试阶段最小化风险,确保迭代安全。
-
部署更新和验证:正式发布新模型后,持续验证效果,自动化工具如Kubernetes简化部署,支持蓝绿部署策略——无缝切换版本,监控指标确认提升,如精度提高10%或延迟降低,团队应记录迭代日志,用于未来优化,整个过程强调敏捷性,每次迭代周期可缩短至几周,适应快速变化。
最佳实践提升迭代效率
高效迭代需结合策略与文化,采用CI/CD(持续集成/持续部署)管道自动化流程,减少人为错误,工具如Jenkins或GitHub Actions集成训练和部署步骤,建立数据治理框架,确保数据新鲜和合规,第三,跨团队协作:数据科学家、工程师和业务人员定期沟通,对齐目标,第四,实施版本控制,用Git管理模型和代码,便于追踪变更,量化ROI(投资回报率),证明迭代价值,某金融公司通过月度迭代,将欺诈检测准确率提升15%,节省数百万损失,这些实践强化迭代可持续性,避免资源浪费。
常见挑战与应对
迭代部署面临障碍,但可策略性化解,数据不足是典型问题:新场景下样本稀缺时,用合成数据或迁移学习补充,模型漂移风险高时,设置更频繁监控,另一个挑战是部署延迟:复杂模型需优化推理引擎,如使用TensorRT加速,文化阻力也常见:团队可能抵触变更,通过培训和文化建设,如分享成功案例,培养迭代思维,技术故障如回滚失败,可通过冗余设计和自动化测试缓解,这些方案确保迭代平稳推进,不中断服务。
迭代部署是AI落地的生命力,推动模型从静态工具演变为动态资产,我认为,团队必须拥抱这一文化:以用户为中心,持续学习并行动,每轮迭代不仅修复缺陷,更释放创新潜力,让AI真正赋能业务,忽视这一点,无异于让宝贵资源沉睡;而积极迭代,则筑就竞争优势的长城。

 13888888888
13888888888

 点击咨询
点击咨询 