AI视觉模型的构建之路:从原理到实践
在人工智能蓬勃发展的浪潮中,视觉模型已成为驱动无数创新的核心引擎,无论是手机解锁的人脸识别、工厂流水线的精密质检,还是自动驾驶汽车洞察复杂路况,其背后都离不开强大AI视觉模型的支持,构建一个切实可用的AI视觉模型,究竟需要经历哪些关键步骤?
第一步:精准定义问题,锚定模型目标 清晰的问题是成功的基石,在着手开发之前,必须深入思考:模型要解决何种具体任务?是识别图像中的特定物体(如检测生产线上的瑕疵零件),对整张图片进行分类(如区分猫狗品种),精确勾勒物体轮廓(如医学影像中的病灶分割),还是理解图像描述生成文字?明确目标直接决定了后续数据收集、模型架构选择及评估标准的制定,切忌目标过于宏大或模糊,聚焦核心需求是关键。

第二步:数据的基石——收集、清洗与标注 数据是模型的生命线,其质量与数量几乎决定了模型性能的天花板。
- 广泛收集: 根据任务目标,尽可能收集覆盖真实应用场景的多样化图像数据,需考虑不同光照条件、拍摄角度、背景复杂度、目标物体形态变化等因素,数据来源可以是公开数据集(如ImageNet、COCO)、网络爬取(注意版权与伦理)、或自主采集。
- 严格清洗: 剔除模糊、无关、重复或低质量的图像,这一步能显著提升后续训练效率和模型精度。
- 精准标注: 这是最耗费人力的环节,依据任务类型进行标注:
- 分类: 为每张图像打上正确类别标签。
- 检测: 用边界框标出目标位置并注明类别。
- 分割: 精确描绘出目标物体的像素级轮廓。
- 数据增强: 在有限数据基础上,通过旋转、翻转、裁剪、缩放、调整亮度对比度、添加噪声等方法人工扩充数据集,增加模型鲁棒性,有效防止过拟合,自动化工具在此环节可大幅提升效率。
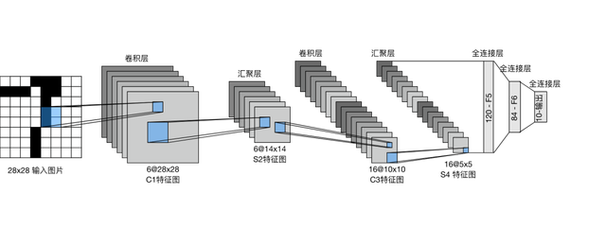
第三步:模型架构的智慧选择 选择或设计合适的神经网络架构是核心技术决策:

- 经典之选(CNN): 卷积神经网络仍是图像处理的基石,ResNet、VGG、MobileNet等经过大规模数据集(如ImageNet)预训练的模型,具有强大的特征提取能力,通过迁移学习,在其基础上针对特定任务进行微调(Fine-tuning),是高效且效果卓越的主流方案,尤其适合数据量相对有限的应用。
- 新锐力量(Transformer): Vision Transformer (ViT) 及其变种展现出在处理图像全局信息上的强大潜力,特别在需要理解复杂场景或长距离依赖的任务中表现突出,正逐渐成为重要选项。
- 定制化设计: 对于极其特殊或前沿的任务,可能需要基于已有架构进行修改或设计全新的网络结构,但这通常需要深厚的研究背景和大量计算资源进行验证。
第四步:模型训练——调优的艺术 选定架构后,进入核心的训练阶段:
- 框架与环境: 使用成熟的深度学习框架(如PyTorch, TensorFlow, PaddlePaddle)搭建模型,强大的GPU算力是加速训练的必备条件,云平台提供了灵活的算力支持。
- 损失函数: 根据任务类型选择匹配的损失函数(如交叉熵用于分类,Smooth L1 Loss用于检测框回归,Dice Loss用于分割)。
- 优化器: Adam、SGD(常配合动量)等优化器负责驱动模型参数更新。
- 超参数调优: 学习率(及其衰减策略)、批次大小(Batch Size)、训练轮次(Epochs)等超参数对模型最终性能影响巨大,需要系统性地进行实验和调整(如网格搜索、随机搜索或更高级的贝叶斯优化),早停法(Early Stopping)是防止过拟合的有效策略。
- 监控与调试: 实时监控训练损失和验证集上的评估指标(如准确率、精确率、召回率、mAP、IoU等),分析学习曲线,及时发现欠拟合或过拟合问题,并调整策略。
第五步:严谨评估与持续优化 模型训练完成并非终点,严谨的评估至关重要:
- 独立测试集: 使用从未参与训练和验证过程的独立测试集进行评估,这是衡量模型泛化能力(处理新数据能力)的黄金标准。
- 全面指标: 不仅看整体准确率,更要分析混淆矩阵,关注模型在哪些类别上表现不佳(如精确率低、召回率低),是否存在特定场景(如光照暗、目标小、遮挡多)下的性能瓶颈。
- 深入分析: 可视化模型的注意力区域、错误预测案例,理解模型决策依据和失败原因。
- 迭代优化: 根据评估结果,可能需要返回调整:收集更多特定场景数据、改进标注质量、尝试不同模型架构或更精细地调整超参数、甚至修改损失函数设计,模型优化是一个持续迭代的过程。
第六步:落地部署与应用 训练好的模型需要集成到实际应用系统中才能发挥价值:
- 模型优化: 为满足部署环境(如移动端、嵌入式设备)对速度和资源的要求,常需对模型进行优化:量化(降低数值精度)、剪枝(移除冗余连接)、知识蒸馏(用大模型指导训练小模型)等技术可有效压缩模型体积、提升推理速度。
- 部署方式: 根据需求选择云端API服务、边缘设备端部署或混合模式。
- 持续监控与更新: 上线后需持续监控模型在实际生产环境中的表现,收集用户反馈和新数据,随着数据分布的变化(Data Drift)或业务需求更新,模型需要定期或触发式地进行重新训练和版本迭代。
构建过程中的关键考量与挑战
- 计算资源: 训练大型视觉模型,尤其从零开始训练,需要强大的GPU集群和可观的时间成本,迁移学习和云服务是缓解此压力的有效途径。
- 数据隐私与伦理: 收集和使用图像数据必须严格遵守相关法律法规(如GDPR),高度重视用户隐私保护,获取明确的知情同意,模型的应用需考虑公平性,避免因训练数据偏见导致歧视性结果。
- 模型可解释性与鲁棒性: 理解模型为何做出特定决策(可解释性)对于高风险应用(如医疗、金融)至关重要,需关注模型对抗对抗性攻击(精心设计的扰动欺骗模型)的鲁棒性。
- 领域专业知识: 在特定领域(如医疗影像分析、工业缺陷检测)构建高效模型,通常需要该领域专家的深度参与,共同定义问题、理解数据特性、评估结果合理性。
构建一个高效、鲁棒的AI视觉模型是一项融合了数据科学、深度学习理论、工程实践和领域知识的系统性工程,从精准定义问题到数据的精心打磨,从模型架构的智慧选择到训练调优的耐心艺术,再到严谨评估和持续迭代,每一步都至关重要,成功的模型并非一蹴而就,它依赖于清晰的目标设定、高质量的数据基石、恰当的技术选型、持续的优化迭代以及对实际应用场景和伦理边界的深刻理解,在探索视觉智能的道路上,技术是工具,而解决真实世界的问题、创造价值才是其根本目的。

 13888888888
13888888888

 点击咨询
点击咨询 