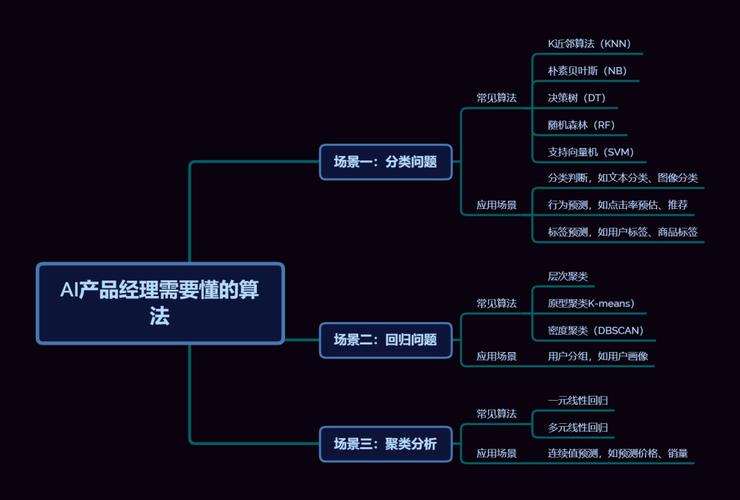
AI算法分类模型:从入门到精通的实用指南
分类模型如同一位经验丰富的决策者,能在纷繁复杂的数据中精准识别规律,当您需要区分客户是否会流失、判断邮件是否为垃圾邮件、识别医疗影像中的病灶时,分类模型就是您的核心工具。
第一步:明确任务与数据准备

- 精准定义目标: 您要区分什么?是用户购买意向(是/否)、产品质量(合格/不合格)、新闻主题分类?清晰定义类别标签至关重要。
- 数据采集与清洗: 收集与目标高度相关的历史数据,清理缺失值、处理异常点、纠正格式错误,高质量数据是模型成功的基石。
- 特征工程: 这是模型效能的关键,将原始数据转化为模型能理解的“语言”,将“用户注册日期”转化为“用户年龄(天)”,对文本进行分词和向量化,对分类变量进行独热编码,特征质量直接影响模型上限。
第二步:模型选择与训练
- 模型初选: 根据数据特点和任务复杂度选择:
- 逻辑回归: 结构简单、解释性强,是二分类的良好起点。
- 决策树: 规则直观,易于理解,适合处理混合类型特征。
- 随机森林/XGBoost/LightGBM: 集成方法,通过组合多棵决策树提升预测精度和泛化能力,是当前结构化数据的主流选择。
- 支持向量机: 在高维空间寻找最优分类边界,尤其适合样本量不大的场景。
- 朴素贝叶斯: 基于概率,计算高效,常用于文本分类。
- 神经网络: 对于图像识别、复杂自然语言处理等任务具有强大表征能力。
- 划分数据集: 将数据分为训练集(用于模型学习)、验证集(用于调优和模型选择)、测试集(用于最终独立评估)。
- 训练过程: 使用训练集数据“喂给”模型,模型自动学习特征与目标标签之间的复杂关系(如决策树学习分裂规则,神经网络调整神经元权重)。
第三步:评估与调优
- 关键指标解读:
- 准确率: 正确预测比例,在类别分布均衡时有效。
- 精确率: 预测为正例的样本中,真正正例的比例(避免误伤)。
- 召回率: 实际正例样本中,被正确预测出的比例(避免遗漏)。
- F1值: 精确率和召回率的调和平均,综合衡量模型。
- AUC-ROC: 评估模型在不同阈值下区分正负样本的能力,值越接近1越好。
- 模型调优: 根据验证集表现调整模型自身的设置项(超参数),如决策树的最大深度、随机森林的树的数量、神经网络的学习率和层数,常用网格搜索或随机搜索等方法寻找最优组合。
- 过拟合警惕: 模型在训练集上表现完美,在验证/测试集上却大幅下滑?这是典型的过拟合,可通过增加数据量、简化模型结构、加入正则化约束或应用交叉验证来缓解。
第四步:部署与应用
- 模型固化: 将训练好的最优模型及其所需预处理步骤打包保存。
- 集成部署: 将模型集成到业务系统:
- 批量预测: 定时处理大量数据(如每晚预测次日可能流失用户)。
- 实时API: 提供接口,供其他系统实时调用(如用户行为触发实时推荐)。
- 嵌入应用: 直接集成到App或网页中(如实时图像分类)。
- 持续监控与更新: 模型不是一劳永逸,持续监控线上预测表现,当发现数据分布变化导致效果下降时,需触发模型重新训练和更新。
实际应用案例
- 金融风控: 某银行使用XGBoost模型分析用户交易、行为、征信数据,实时评估贷款申请风险等级,自动化审批率提升30%,坏账率有效降低。
- 医疗诊断辅助: 某三甲医院部署基于卷积神经网络的影像识别模型,辅助医生筛查CT影像中的早期肺结节,提高检出效率。
- 电商推荐: 某平台利用逻辑回归和深度模型融合,根据用户实时点击、浏览、加购行为预测购买转化概率,动态调整商品排序,点击转化率提升显著。
- 工业质检: 某制造企业应用SVM模型于生产线摄像头采集的产品表面图像,实时识别划痕、凹陷等缺陷,替代部分人工目检。
根据经验,成功应用分类模型的关键在于三点:理解业务需求本质、投入精力做好特征工程、建立持续监控迭代的闭环流程,模型本身是强大的工具,但驱动价值的始终是使用者的目标清晰度与对数据的深刻洞察,没有最好的模型,只有最合适的模型和应用方式。

 13888888888
13888888888

 点击咨询
点击咨询 