在人工智能技术快速发展的当下,许多开发者和企业都希望将特定功能或知识有效整合到已有模型中,以提升其性能或适应新场景,这一过程通常被称为“注入”,但需要注意的是,这里所说的“注入”并非指侵入式或破坏性的操作,而是指通过合法、结构化的技术手段对模型进行增强或改造。
实现这一目标的核心思路,是通过额外训练或架构调整,使模型掌握新知识或获得新能力,目前常见的方法主要包括微调训练、知识蒸馏以及插件式扩展等,每种方法各有特点,适用于不同需求和资源条件。
微调训练是目前最普遍采用的方式,其原理是在预训练模型的基础上,使用新的、针对特定领域或任务的数据集进行第二轮训练,在这个过程中,模型原有的参数会根据新数据逐渐调整,从而将新知识“融入”其内部表示,一个通用的图像识别模型,可以通过大量医学影像数据进行微调,从而获得辅助诊断的能力,微调的关键在于学习率的设置和数据的质量,过高的学习率可能导致“灾难性遗忘”,即模型丢失原有知识;而低质量数据则会使模型产生偏见或错误。
另一种高效的方法是知识蒸馏,它通常涉及一个大型、高性能的教师模型和一个小型的学生模型,教师模型已经具备了所需的新能力,其作用是通过生成软标签(包含类别概率分布的丰富信息)来指导学生模型的学习,学生模型的目标不是简单地模仿输出结果,而是学习教师模型的决策逻辑和知识表征,这种方式特别适合将大型模型的能力“注入”到更轻量级的模型中,以便在计算资源有限的边缘设备上部署。
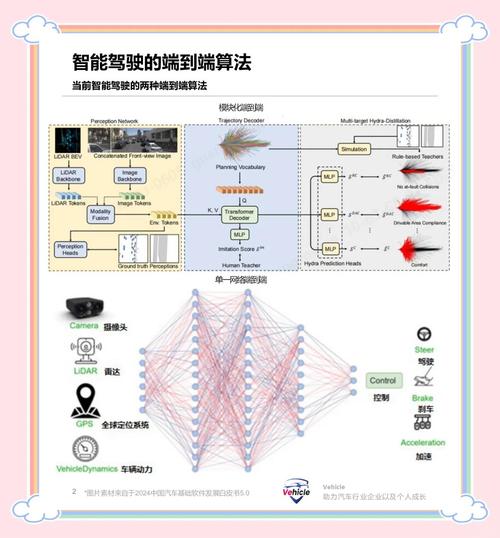
插件式扩展为模型注入能力提供了灵活度更高的解决方案,这种方法不改变模型的核心参数,而是通过附加外部组件或适配器来实现功能增强,可以为大型语言模型连接一个外部知识库,当模型遇到需要事实性知识的问题时,它学会生成查询并从知识库中检索相关信息,再将信息整合到最终回答中,这种方式保持了主模型的稳定性,同时又能动态地增加新的知识源。
无论选择哪种路径,成功为AI软件注入新模型或新能力都必须建立在高质量的数据基础之上,数据的规模、清洁度、相关性和无偏见性,直接决定了最终模型的性能上限和伦理安全下限,低质或带有偏见的数据不仅无法提升模型,反而会引入新的问题和风险。
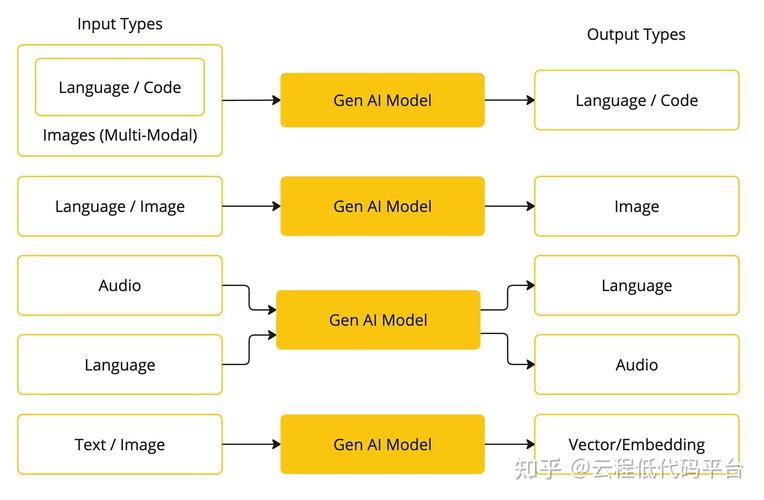
从工程实践的角度看,整个注入过程需要严谨的测试和评估,不能仅凭单一指标(如准确率)就判断成功,还必须进行全面的评估,包括模型在不同子群体上的公平性、在对抗样本下的鲁棒性以及输出结果的可解释性,这是一个循环迭代的过程,需要根据评估结果反复调整数据和模型参数。
个人看来,为AI模型注入能力更像是一门精密的艺术,而不仅仅是技术操作,它要求开发者不仅深刻理解模型架构和算法,更要对其应用场景、伦理边界和社会影响有清醒的认识,未来的发展趋势将是自动化、标准化工具的出现,以降低这项工作的技术门槛,但核心的决策判断——选择注入什么、为何注入以及如何负责任的注入——将始终依赖于人的智慧和责任心。

 13888888888
13888888888

 点击咨询
点击咨询 