AI建模修复模型作为一项前沿技术,正逐渐改变我们对图像、视频及三维模型等数字内容的处理方式,它不仅能够有效修复损坏或低质量素材,还能显著提升内容的表现力和可用性,对于创作者、研究人员乃至普通用户而言,掌握其基本使用方法具有重要实际意义。
要理解AI建模修复模型的核心机制,需从人工智能的基本原理入手,这类模型通常基于深度学习框架,尤其是卷积神经网络(CNN)或生成对抗网络(GAN),它们通过大量数据训练,学习图像或模型中的特征与模式,进而实现对缺失、模糊或噪声干扰部分的有效推测与填补,在图像修复中,模型能够根据周围像素信息,智能生成与整体协调的新内容。
使用AI建模修复模型的具体步骤虽因不同软件或平台而略有差异,但一般遵循以下流程:
用户需准备待修复的素材,这可能是模糊的老照片、部分损坏的数字图像,或细节缺失的三维网格模型,高质量输入虽非绝对必要,但一定程度上有助于提升最终效果,建议在前期对素材进行基础预处理,如调整亮度对比度、裁剪无关区域或统一格式,以减少模型干扰。

接下来是选择适合的修复工具或平台,目前市面上已有多种集成AI修复功能的软件,包括开源工具和商业解决方案,部分产品专注于图像超分辨率,有些则擅长修复划痕或噪点,还有的可处理视频帧或三维点云,用户应根据具体需求,选择功能匹配的工具,安装并启动相应程序后,通常可看到直观的界面引导操作。
用户需导入素材并设置修复参数,多数工具提供自定义选项,如修复强度、细节增强程度、输出分辨率等,对于不熟悉的用户,建议先从默认配置开始,逐步根据效果调整,处理人像照片时,过高强度可能导致面部失真;而修复风景类图片时,则可适当提高细节增强以恢复纹理。
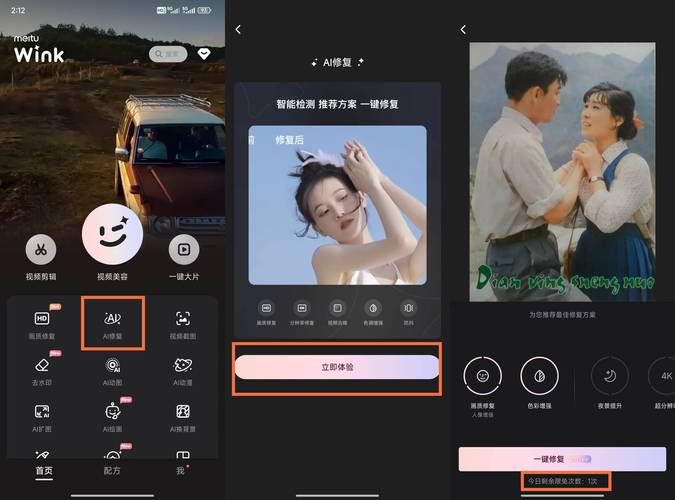
完成参数设置后,启动修复过程,根据素材大小及模型复杂度,处理时间可能从数秒到数小时不等,一些工具支持实时预览或阶段性结果展示,方便用户中途调整策略,在此期间,计算机将调用已训练的神经网络对输入内容进行分析与重构,逐层优化输出质量。
修复完成后,务必仔细评估输出结果,AI生成内容虽智能,但仍可能存在瑕疵,如逻辑不一致的区域或过度平滑的细节,建议从整体协调性、边缘过渡、纹理真实性等多角度进行检查,若效果未达预期,可尝试调整参数重新处理,或结合其他编辑手段进行后期完善。
值得注意的是,AI修复模型并非万能,其效果受训练数据质量、算法设计及具体应用场景的多重影响,对于严重损坏或信息极度缺失的素材,可能出现推测错误或不合实际的修补结果,人工干预或专业处理仍是不可或缺的。
使用者应始终关注伦理与版权问题,AI修复技术可能涉及对原有内容的改写与再创作,在商业使用或公共传播前,需确保不侵犯他人权益,尤其当处理历史影像或他人作品时。
从个人视角看,AI建模修复模型的价值不仅在于技术实现,更在于其为创意表达与文化遗产保护提供的全新可能,它降低了专业修复的门槛,让更多人能参与到数字记忆的保存与焕新中,工具始终是工具,真正的智慧在于使用者如何平衡自动化与人性化判断,在效率与真实之间找到最佳契合点。

 13888888888
13888888888

 点击咨询
点击咨询 