近年来,人工智能技术发展迅猛,尤其是对话模型逐渐走入大众视野,许多用户开始尝试在本地部署AI对话模型,既保护隐私又享受离线可用的便利,如果你也对这一技术感兴趣,希望了解如何在本地使用AI对话模型,本文将为你提供一份实用指南。
要运行本地AI对话模型,首先需要明确自己的硬件条件,通常情况下,这类模型对计算资源有一定要求,尤其是显存,一些轻量级模型可能在8GB显存的消费级显卡上即可运行,而更大规模的模型可能需要更高配置,如果你的设备性能有限,也不必担心,目前已有不少经过优化的模型可在CPU环境下运行,只是响应速度可能略慢。
选择合适的模型是成功部署的关键一步,当前较常见的开源模型包括LLaMA、Alpaca、ChatGLM等,它们各有特点,适用于不同场景,有些模型在多轮对话方面表现优异,有些则更擅长特定领域的知识问答,建议初学者从知名度较高、社区支持较好的模型入手,这样在遇到问题时更容易找到解决方案。
模型下载完成后,下一步是部署环境,大多数AI对话模型依赖Python运行,并且需要安装特定的深度学习框架,如PyTorch或TensorFlow,还需安装模型运行所需的依赖库,如果你不熟悉命令行操作,也可以尝试一些集成了图形界面的开源工具,它们大大降低了使用门槛,通过简单点击即可完成模型加载与对话。
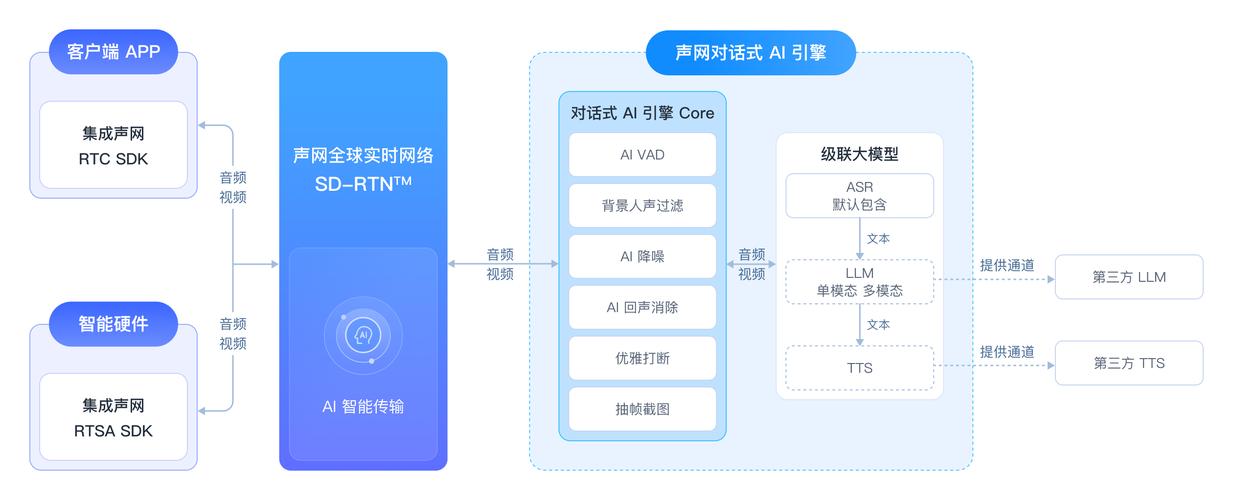
准备工作就绪后,即可启动模型进行对话,首次运行可能需要加载模型参数,这会消耗一些时间,请耐心等待,成功启动后,你可以在输入框中键入问题或指令,模型将生成回应,值得注意的是,本地运行的模型可能无法像在线服务那样实时更新知识库,因此它的回答基于训练时的数据,对非常近期的事件可能无法给出准确答案。
使用过程中,你可能会发现模型偶尔表现不尽如人意,例如回答不够精准或逻辑出现偏差,这通常是正常的,因为当前技术尚未完美,你可以通过优化提问方式、提供更清晰的上下文或多尝试几次来改善回答质量,一些工具支持对模型进行微调,即通过额外数据训练使其更适应特定任务,但这需要一定的专业知识。
除了常规的文字对话,一些本地AI对话模型还支持语音输入、多模态交互等高级功能,你可以通过语音提出问题并获取回答,或者上传图片让模型进行分析并描述内容,这类功能进一步拓展了应用场景,使得人机交互更加自然多样。
关于实用性,本地AI对话模型能胜任多种任务,它可以作为编程助手,帮你调试代码或解释复杂算法;也可以充当创意伙伴,协助撰写文案、生成故事大纲;甚至能成为学习导师,解答专业知识或帮助梳理知识体系,其用途广泛,取决于你的需求和想象力。
在数据安全日益受到重视的今天,本地部署的优势显而易见,所有对话数据仅保存在本地设备,不会上传到云端,避免了隐私泄露的风险,对于企业用户或对数据敏感的个人而言,这一点尤为重要。
从技术发展趋势来看,本地AI对话模型正变得越来越高效和易用,随着模型压缩技术和硬件加速能力的提升,我们有望在更轻量的设备上运行更强大的模型,进一步降低使用门槛。
无论如何,AI对话模型始终是一种工具,它的价值取决于使用者如何利用,拥抱新技术的同时,我们也应保持理性,理解其优势与局限,才能更好地让它为生活和工作赋能。

 13888888888
13888888888

 点击咨询
点击咨询 