人工智能模型创造视频的过程,正逐渐改变我们制作和消费视觉内容的方式,想象一下,只需输入一段文字描述,AI就能生成一段流畅的视频片段,这听起来像是科幻电影的情节,但如今已成为现实,这种技术不仅提升了创作效率,还为各行各业带来了新的可能性,本文将深入探讨AI模型如何一步步实现视频生成,从基础原理到实际应用,帮助读者理解这一前沿领域。
要理解AI模型如何创造视频,首先需要了解其核心机制,AI视频生成依赖于深度学习模型,特别是生成式模型,如生成对抗网络(GANs)和扩散模型,这些模型通过分析大量视频数据进行训练,学习视频中的时空关系,即帧与帧之间的动态变化,一个模型可能被训练来识别人类动作的模式,如走路或说话,然后根据输入的文字提示生成相应的视频序列。

训练过程是视频生成的关键环节,AI模型需要海量的视频数据集作为学习素材,这些数据通常包含各种场景、物体和动作,在训练阶段,模型会逐帧分析视频,提取特征如颜色、形状和运动轨迹,通过反复调整内部参数,模型逐渐学会预测下一帧的内容,从而构建出连贯的视频流,这个过程类似于人类学习绘画:先观察大量作品,再尝试自己创作,不同的是,AI的速度和规模远超人类,能在几小时内处理数百万帧数据。
具体到技术细节,扩散模型是目前视频生成的主流方法,它通过逐步添加和去除噪声来生成内容,模型从一个随机噪声图像开始,然后根据文字指令逐步“去噪”,最终形成清晰的视频帧,这种方法能产生高质量、细节丰富的输出,例如生成逼真的自然景观或人物动画,另一个常见技术是变分自编码器(VAE),它通过编码和解码过程压缩和重建视频数据,实现高效生成。

AI模型创造视频的应用场景十分广泛,在娱乐产业,它可用于快速制作动画短片或特效,降低制作成本,教育领域,AI能生成互动式教学视频,使学习过程更生动,在医疗或科研中,AI视频生成能模拟复杂现象,如细胞分裂或气候变化,帮助研究人员可视化数据,这些应用不仅展示了技术的实用性,还体现了其社会价值。
AI视频生成也面临挑战,模型可能产生不连贯或失真的画面,尤其在处理快速运动时,数据偏差是另一个问题:如果训练数据缺乏多样性,生成的内容可能带有偏见,计算资源需求高,限制了小规模应用,解决这些挑战需要持续优化算法和扩大数据集。
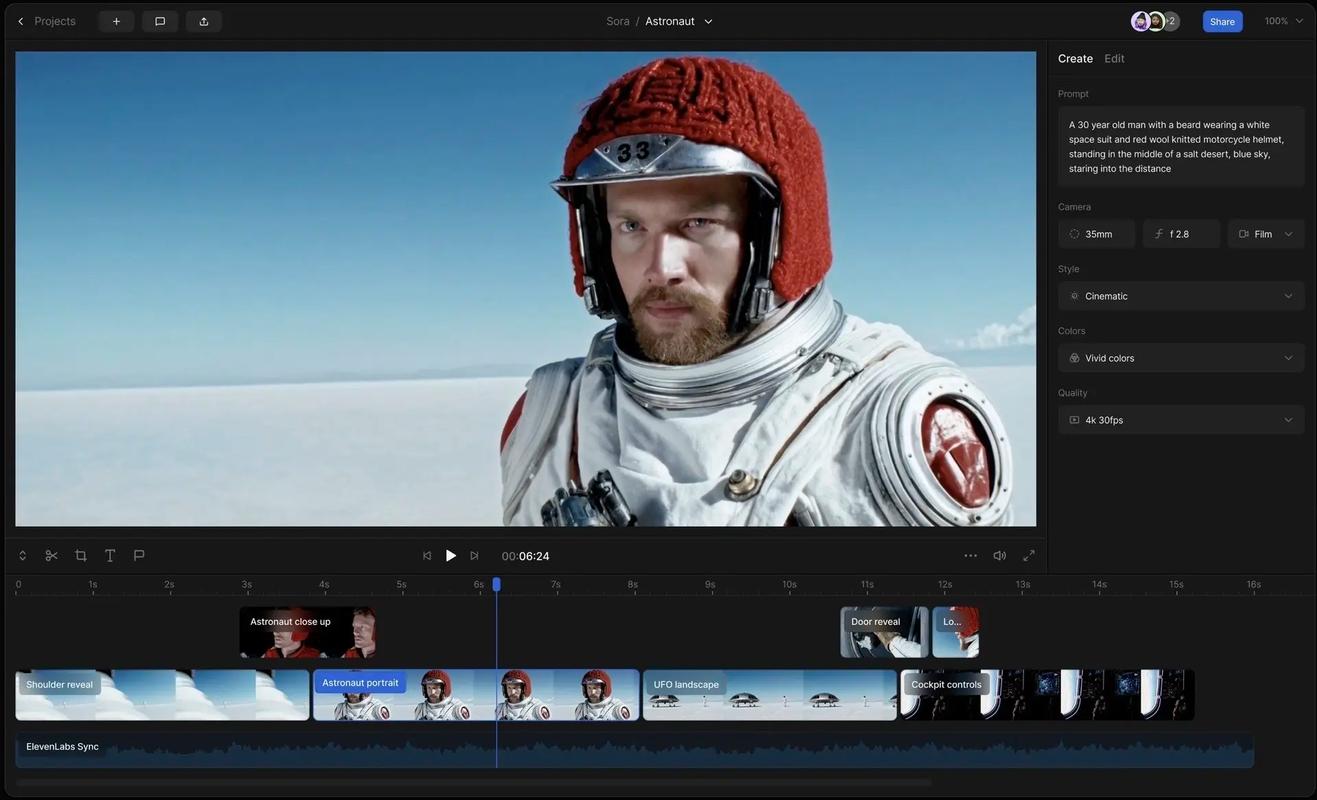
从个人角度来看,AI视频生成技术代表了人类创造力的延伸,它并非取代人类艺术家,而是作为一种工具,激发新的灵感,随着模型变得更智能,我们可能会看到更个性化的视频内容,例如根据用户情绪生成定制影片,但这也引发伦理思考,如如何防止滥用或确保透明度,作为网站站长,我认为普及这类知识至关重要,它能帮助公众理性看待技术发展,共同塑造负责任的AI未来。

 13888888888
13888888888

 点击咨询
点击咨询 