人工智能模型是如何“理解”事物的?这个问题常常让人感到好奇甚至困惑,当我们说一个AI系统能识别图像、翻译语言或推荐电影时,它真的在“理解”内容吗?答案可能比你想象的更复杂,也更简单。
要探讨AI模型的理解方式,我们首先需要明确一点:AI的理解并非人类意义上的意识或情感体验,而是一种基于数学和统计的模式匹配过程,它通过大量数据学习规律,并应用这些规律来做出预测或决策。
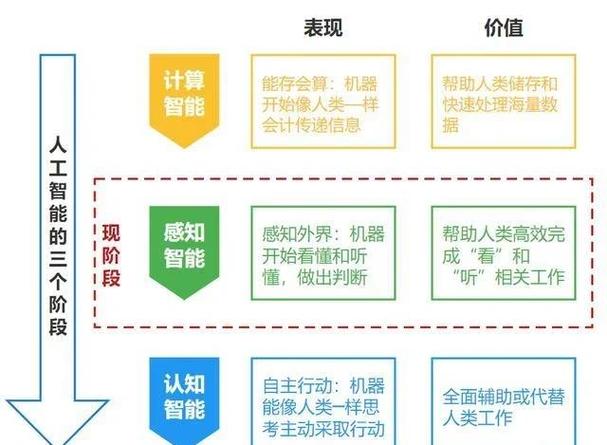
AI理解的基础:数据与算法
AI模型的核心是数据和算法,想象一下教一个孩子认识猫:你需要展示许多猫的图片,并反复告诉孩子“这是猫”,AI的学习过程类似,但规模更大、速度更快,模型通过处理海量数据——比如数百万张标注好的猫的图片——来识别猫的共同特征,比如耳朵形状、毛发纹理等,这些数据是AI“理解”世界的原材料。
算法则是学习的引擎,以深度学习为例,它模拟人脑的神经网络结构,通过层层节点处理信息,每一层都会提取数据的特定特征:底层可能识别边缘和颜色,中层组合成形状,高层则形成更抽象的概念,模型学会将输入(如图片)映射到输出(如“猫”的标签),这种映射不是基于逻辑推理,而是基于概率统计,模型本质上是在计算“给定这些像素,是猫的可能性有多大”。
训练过程:从无知到“认知”
AI模型的训练就像一场密集的课程,它通过反复试错来优化自己,训练分为几个阶段:
- 前向传播:模型接收输入数据,并生成一个预测结果,给出一张图片,它可能输出“80%是猫,20%是狗”。
- 损失计算:将预测与真实标签比较,计算误差,如果图片确实是猫,但模型只给了80%置信度,误差就产生了。
- 反向传播:模型根据误差调整内部参数(如权重和偏置),让下一次预测更准确,这个过程通过梯度下降等优化算法实现,目标是最小化整体误差。
经过成千上万次迭代,模型逐渐“学会”了数据中的模式,在自然语言处理中,模型会从文本中学习词汇的关联性——苹果”更常与“水果”而非“公司”一起出现,但这取决于上下文,这种学习让模型能生成连贯的回复或翻译句子,但它并不真正懂得语言的含义,只是统计了词汇共现的概率。

实际应用中的“理解”
在日常应用中,AI的理解能力已经相当惊人,以自动驾驶汽车为例:它通过摄像头和传感器收集道路数据,识别行人、车辆和交通标志,模型不是“知道”行人的概念,而是学会了像素模式与“行人”标签的对应关系,当它刹车避让时,是基于历史数据中类似场景的统计规律做出的决策。
另一个例子是语言模型,如用于聊天机器人或搜索引擎的AI,它们通过分析互联网上的文本,学习语法结构和语义关联,当你问“今天天气如何”,模型可能生成一个回答,因为它从训练数据中看到过无数类似对话,但这种“理解”是表面的:模型不会关心天气本身,只是匹配了最可能的响应模式。
局限性与挑战
尽管AI表现优异,它的理解方式有根本局限,AI缺乏常识和上下文感知,人类能基于经验推断未明说的事实,但AI可能被歧义难倒,句子“他打开了窗户,因为房间太热了”,人类自然理解因果关系,而AI可能只学到词汇序列的统计关联。
AI模型容易受数据偏见影响,如果训练数据中某些群体或观点占比过高,模型会复制这些偏见,导致不公平的输出,招聘AI可能因历史数据中男性程序员更多,而低估女性候选人的能力。
AI的理解是黑箱式的,即使我们知道模型如何计算,也很难解释为什么某个决策被做出,这在医疗或金融等高风险领域尤其成问题。
个人观点
从我的角度看,AI模型的理解本质上是工具性的进步,它让我们能处理超人类规模的数据,但离真正的智能还有距离,结合因果推理和伦理框架的AI或许能更接近人类理解,但这需要跨学科的努力,作为技术使用者,我们应欣赏AI的能力,同时清醒认识其边界——它不是魔法,而是数学的延伸。

 13888888888
13888888888

 点击咨询
点击咨询 