随着人工智能技术的不断演进,AI模型的选择已成为企业和开发者面临的关键决策,无界AI模型,作为一种广泛应用的智能工具,其选择过程需要综合考虑技术、成本、易用性等多方面因素,本文将从实际应用角度出发,探讨如何科学地挑选适合的无界AI模型,帮助访客在复杂的技术环境中做出明智选择。
理解无界AI模型的基本特性
无界AI模型通常指那些具有高度灵活性和可扩展性的AI系统,能够适应不同场景的需求,如图像识别、自然语言处理或预测分析,选择这类模型时,首先需明确自身需求:是用于实时处理还是批量分析?目标精度要求如何?如果应用场景涉及高并发用户请求,模型的处理速度和稳定性就比纯准确率更重要,相反,若用于医疗诊断或金融风控,准确性则成为首要指标,通过定义清晰的目标,可以缩小选择范围,避免盲目跟风。
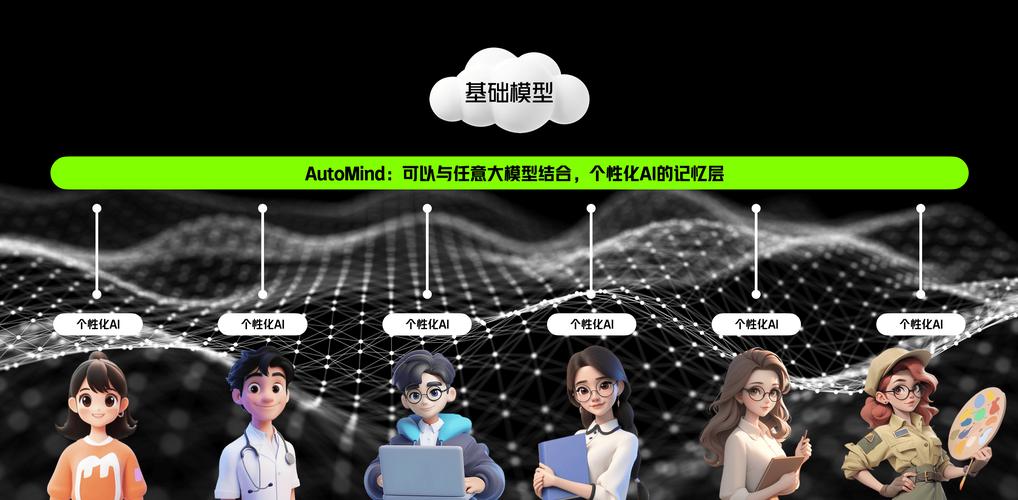
评估性能指标:从准确率到效率
性能是选择AI模型的核心要素,常见的指标包括准确率、召回率、F1分数等,但这些数字并非绝对标准,实际应用中,还需关注模型的推理速度、资源占用和鲁棒性,一个在测试集上表现优异的模型,可能在真实环境中因数据分布变化而失效,建议通过A/B测试或模拟环境验证模型表现,考虑模型的可解释性:在监管严格的行业,如金融或法律,黑箱模型可能带来风险,而可解释AI模型则更受青睐。
成本与资源考量:平衡投入与产出
AI模型的部署往往涉及显著的成本,包括硬件资源、云服务费用和维护开销,无界AI模型可能支持分布式计算,但这也意味着更高的初始投资,选择时,需评估总拥有成本(TCO):开源模型虽免费,但需要专业团队定制;商用模型则提供一站式服务,但许可费用可能高昂,模型的大小和复杂度直接影响资源需求——轻量级模型适合移动端,而大型模型则需要GPU集群,建议从长期业务规划出发,选择性价比高的方案,避免因短期节省导致后续扩展困难。
易用性与集成能力:降低技术门槛
对于非专业团队,模型的易用性至关重要,无界AI模型应提供清晰的API文档、预训练权重和示例代码,以加速集成过程,工具链的完善程度也很关键:是否支持主流框架如TensorFlow或PyTorch?是否有可视化界面辅助调试?一些模型平台提供拖拽式建模,大大降低了开发难度,考虑与现有系统的兼容性,避免因技术栈冲突引发额外工作量,如果团队技术实力有限,优先选择社区活跃、文档丰富的模型,以减少学习成本。
可扩展性与未来适应性
技术环境瞬息万变,AI模型需具备一定的可扩展性以适应未来需求,无界AI模型应支持模块化升级,例如通过迁移学习快速适应新任务,关注模型的更新频率和生态发展:一个持续优化的模型更能应对数据漂移或政策变化,在选择时,可以考察供应商的路线图或行业趋势,确保模型不会迅速过时,当前多模态AI正兴起,若模型能融合文本、图像等多源数据,将更具长期价值。

社区支持与可信度保障
强大的社区背景能显著提升模型的可信度,无界AI模型若有活跃的开源社区或权威机构背书,往往更值得信赖,社区不仅提供技术答疑,还能贡献优化代码和案例分享,降低使用风险,评估模型的透明性:是否公开训练数据和方法?是否有第三方审计报告?在E-A-T(专业性、权威性、可信度)框架下,选择那些有实证研究支持的模型,能增强决策的可靠性,学术论文中广泛引用的模型,通常比未经验证的方案更安全。
个人观点
在AI模型选择中,我认为关键在于找到技术先进性与实用性的平衡点,无界AI模型并非越复杂越好,而是应贴合业务场景,以最小成本实现最大价值,建议从业者从小规模试点开始,逐步迭代优化,避免一次性投入过大风险,成功的模型选择源于对需求的深刻理解,而非盲目追求前沿技术。

 13888888888
13888888888

 点击咨询
点击咨询 