在数字创意浪潮席卷而来的今天,Stable Diffusion(简称SD)这个名字已经不再陌生,它像一扇通往无限想象世界的大门,让每个人都有可能成为“神笔马良”,对于许多刚接触它的朋友来说,面对复杂的参数和操作界面,常常会感到无从下手,这篇文章,就将为您系统地梳理SD AI模型的使用方法,带您从入门到精通。
第一步:搭建你的数字画室

在使用SD之前,你需要一个能够运行它的环境,目前主要有以下几种方式:
本地部署:这是最自由、最不受限制的方式,你需要在你的电脑上安装一系列软件,包括Python、Git以及SD的源代码,这个过程对新手有一定技术门槛,并且对电脑硬件(尤其是显卡,推荐NVIDIA显卡且显存不低于6GB)有较高要求,优点是数据完全私有,可以无限制地使用各种模型和插件。

云端部署:这是目前对新手最友好的选择,你无需拥有高性能电脑,只需租赁云端的GPU服务器,按使用时长付费,服务商会提供预装好环境的系统镜像,你只需连接上去即可使用,这省去了繁琐的环境配置过程,让你能快速上手。
在线Web工具:一些平台提供了在线生成服务,你只需打开网页,上传图片或输入提示词即可获得结果,这种方式最为便捷,但通常会有生成次数、分辨率或内容的限制,自由度最低。
对于希望深入学习和长期使用的创作者而言,本地部署或云端部署是更值得投入的方向。
第二步:认识你的核心工具——WebUI
无论选择哪种部署方式,你最终操作的界面大概率是 Stable Diffusion WebUI(例如著名的 AUTOMATIC1111 版本),这个基于浏览器的图形界面,将SD复杂的命令行操作转化为直观的按钮和滑块,极大地降低了使用难度。
初次打开WebUI,你可能会被众多的选项卡和参数所震撼,但请不必担心,我们只需先关注几个核心区域:
- 文生图/图生图:这是两个最主要的模式。“文生图”通过文字描述生成图像;“图生图”则允许你上传一张图片,并依据文字提示对其进行修改、重绘或风格迁移。
- 提示词框:这是你与AI沟通的“语言”,上方的框是正向提示词,描述你希望画面中出现的内容;下方的框是负面提示词,描述你不希望出现的内容。
- 模型选择:这是SD的灵魂所在,你需要在这里加载不同的基础模型或Checkpoint模型,不同的模型擅长不同的风格,如写实、二次元、奇幻等。
- 生成按钮:一切的开始。
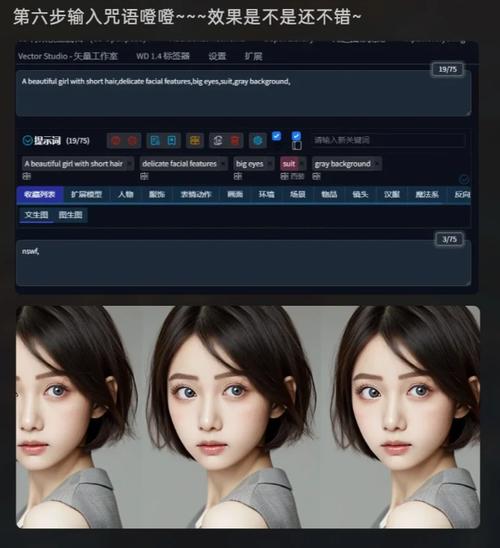
第三步:掌握与AI沟通的艺术——提示词工程
提示词的质量直接决定了生成图像的效果,写好提示词,是一门需要不断练习的艺术。
正向提示词的构成:
- 主题:清晰描述画面的核心,一个穿着汉服的女孩”。
- 环境与背景:在樱花盛开的古典庭院里,月光下”。
- 细节与质量:这是提升画面质感的关键,常用词汇如“大师级作品、最佳质量、极其详细、电影光影、8K分辨率”等。
- 风格与艺术家:可以指定风格,如“水彩画、赛博朋克”,或参考艺术家风格,如“by Greg Rutkowski”(一位以奇幻风格闻名的数字画家)。
负面提示词的常见内容:
- 画面瑕疵:模糊、低质量、多余的手指、畸形的脸部、水印等。
- 不想要的元素:如果不希望出现文字,可以加入“文字、签名”。
小技巧:使用英文提示词通常效果更好,并且用逗号分隔不同概念的词汇,权重调整可以通过 (word:1.2) 来增强某个词的权重,或用 [word:0.8] 来减弱。
第四步:探索模型的广阔世界
SD的魅力在于其开放生态,全球的开发者与艺术家训练了成千上万的专用模型,你不需要从零开始训练,只需下载别人训练好的模型(通常是 .safetensors 或 .ckpt 文件),放入本地指定的文件夹即可在WebUI中调用。
这些模型主要分为:
- 基础模型:如 SD 1.5, SDXL,它们是生成能力的基石。
- Checkpoint 模型:融合了特定风格或主题的大模型,可以直接产出高质量且风格统一的图像,例如国风、科幻、动漫模型等。
- LoRA 模型:一种小型、高效的微调模型,常用于复现特定人物、画风或物件,可以与大模型结合使用,实现更精细的控制。
多尝试不同的模型,是找到属于你自己风格的重要途径。
第五步:精细调控——理解关键参数
在提示词和模型之后,参数的调整能让你的作品更上一层楼。
- 采样步数:AI从噪声中绘制图像的迭代次数,步数太低,画面不完整;步数太高,可能带来不必要的细节变化且耗时增长,20-30步是一个常见的范围。
- CFG Scale:提示词相关性,值越低,AI自由发挥度越高;值越高,AI会越严格地遵守你的提示词,通常在7-12之间调整。
- 种子:决定了生成图像的初始噪声,固定种子值,在其它参数不变的情况下,你可以生成完全相同的图像,这对于微调某张图至关重要。
进阶之路:从生成到创造
当你熟悉了以上基础操作后,便可以探索更强大的功能:
- ControlNet:这是一个革命性的插件,它允许你精确控制生成图像的构图、姿势、边缘等,你可以上传一张人物姿势草图,让AI严格按照这个姿势生成一个全新的角色;或者上传一张建筑线稿,让AI为其上色并丰富细节。
- Img2Img 的重绘强度:在图生图模式下,这个参数决定了新图像与原始图像的差异程度,低强度适合微调颜色和风格,高强度则可以实现颠覆性的改变。
- 局部重绘:允许你只对图片的特定区域进行修改,例如替换一个物品,或者修复一个瑕疵的脸部。
在我看来,SD不仅仅是一个工具,它更是一位充满潜力的创意伙伴,它的价值不在于替代人类艺术家,而在于放大我们的想象力,学习的初期或许会伴随困惑与试错,但每一次参数的调整,每一组提示词的尝试,都是与这位伙伴增进默契的过程,技术会退居幕后,真正闪耀的,永远是你心中那个独一无二的创意世界,就请打开你的SD,输入第一行提示词,开始这场奇妙的创造之旅吧。

 13888888888
13888888888

 点击咨询
点击咨询 