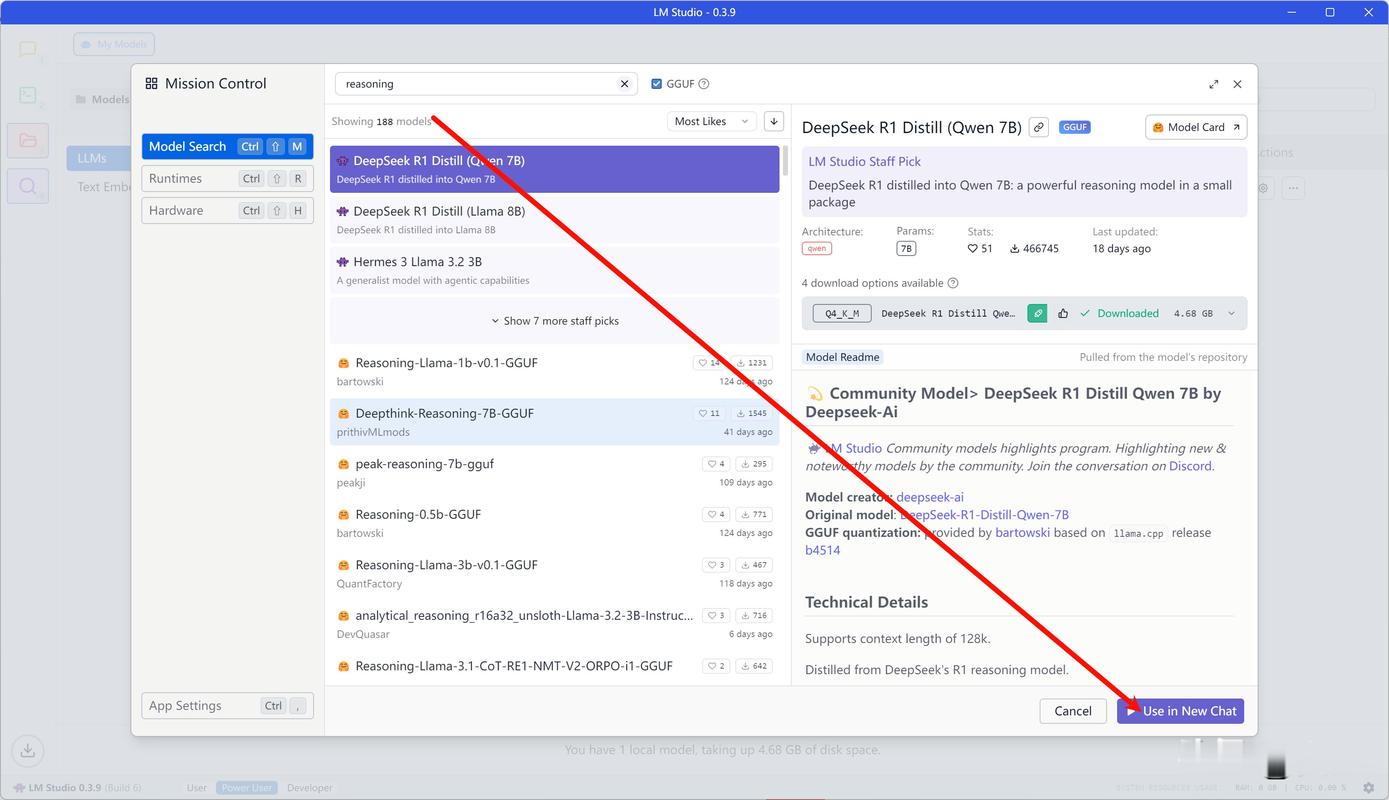
在数字化技术快速发展的今天,本地部署AI模型已成为许多开发者、企业甚至个人用户的重要需求,无论是为了数据隐私保护,还是提升计算效率,掌握本地部署的核心方法都至关重要,本文将以实用为导向,系统讲解本地AI模型部署的全流程,帮助读者避开常见误区,高效完成任务。
第一步:环境搭建与工具准备
部署AI模型前,需确保本地环境满足运行条件,硬件方面,建议配备至少8GB内存的计算机,若涉及图像或大语言模型,推荐使用NVIDIA显卡以支持GPU加速,软件环境需安装以下基础工具:
- Python环境:推荐安装Anaconda,便于管理依赖库。
- 深度学习框架:根据模型类型选择TensorFlow、PyTorch或Keras,可通过
pip install命令安装。 - CUDA工具包(如使用NVIDIA显卡):需与显卡驱动版本匹配,可参考NVIDIA官网文档。
- 代码编辑器:VS Code或PyCharm等工具可提升开发效率。
避坑提示:避免直接安装最新版本框架,部分模型可能依赖特定版本,建议在模型文档中确认兼容性。
第二步:模型获取与格式转换
本地部署的模型通常来源于两种途径:
- 预训练模型:从开源平台(如Hugging Face、官方GitHub仓库)下载已训练好的模型文件(格式多为
.pt、.h5或.onnx)。 - 自定义模型:通过TensorFlow或PyTorch训练后导出为可部署格式。
若模型格式与部署环境不兼容,需进行格式转换,将PyTorch模型转换为ONNX格式:
import torch
model = torch.load('model.pth')
dummy_input = torch.randn(1, 3, 224, 224) # 输入张量需与模型匹配
torch.onnx.export(model, dummy_input, 'model.onnx') 第三步:部署与接口封装
本地部署的核心目标是将模型封装为可调用的服务,常用方法包括:

- 使用轻量级Web框架:如Flask或FastAPI,将模型包装成HTTP API接口。
from flask import Flask, request import numpy as np
app = Flask(name) model = load_model('model.h5') # 加载本地模型
@app.route('/predict', methods=['POST']) def predict(): data = request.json['data'] prediction = model.predict(np.array(data)) return {'result': prediction.tolist()}
if name == 'main': app.run(host='0.0.0.0', port=5000)
2. **容器化部署**:通过Docker将模型与环境打包,确保跨平台一致性,编写Dockerfile后,执行`docker build -t ai-model .`即可生成镜像。
**关键技巧**:启用多线程或异步处理(如Gunicorn搭配Flask)可提升并发性能。
---
### **第四步:性能优化与测试**
部署完成后,需验证功能并优化效率:
- **功能测试**:使用Postman发送测试请求,检查返回结果是否符合预期。
- **性能压测**:通过Locust或JMeter模拟高并发请求,监控内存与CPU占用。
- **加速策略**:
- **模型量化**:将浮点权重转换为低精度(如INT8),减少计算资源消耗。
- **硬件加速**:启用CUDA或OpenVINO工具优化推理速度。
- **缓存机制**:对频繁调用的结果进行缓存,降低重复计算开销。
---
### **第五步:安全与长期维护**
本地部署需重视数据安全与模型更新:
1. **访问控制**:通过API密钥或IP白名单限制调用权限。
2. **日志监控**:记录请求日志,便于排查异常行为。
3. **版本管理**:使用Git跟踪模型迭代,避免覆盖导致服务中断。
4. **定期更新**:关注框架漏洞公告,及时升级依赖库。
---
部署本地AI模型并非一劳永逸,而是一个持续优化的过程,从环境配置到性能调优,每个环节都需要结合具体场景灵活调整,尤其需注意平衡资源占用与响应速度,避免过度追求精度导致硬件成本飙升,建议初次部署时从小型模型入手,逐步积累经验,再扩展至复杂场景。
技术发展日新月异,但核心逻辑始终围绕“需求驱动工具选择”,无论是选择轻量级框架还是重型架构,最终目标始终是让模型稳定、高效地服务于业务。
 13888888888
13888888888

 点击咨询
点击咨询 