在当今科技飞速发展的时代,人工智能(AI)已成为我们日常生活的一部分,越来越多的人开始关注在本地设备上运行AI模型,这不仅节省成本,还提升了数据隐私和控制权,如果你也对如何创建和运行本地AI模型感兴趣,本文将一步步为你解析整个过程,无论你是技术爱好者还是初学者,都能从中受益。
理解什么是本地AI模型至关重要,本地AI模型指的是在个人电脑、服务器或其他设备上部署和运行的AI系统,无需依赖互联网或云服务,这种方式避免了数据泄露风险,减少了延迟,并允许用户完全自定义模型,常见的本地AI应用包括语言生成、图像识别和预测分析等,你可以使用本地模型处理敏感文档或进行实时决策,而不必担心第三方干预。
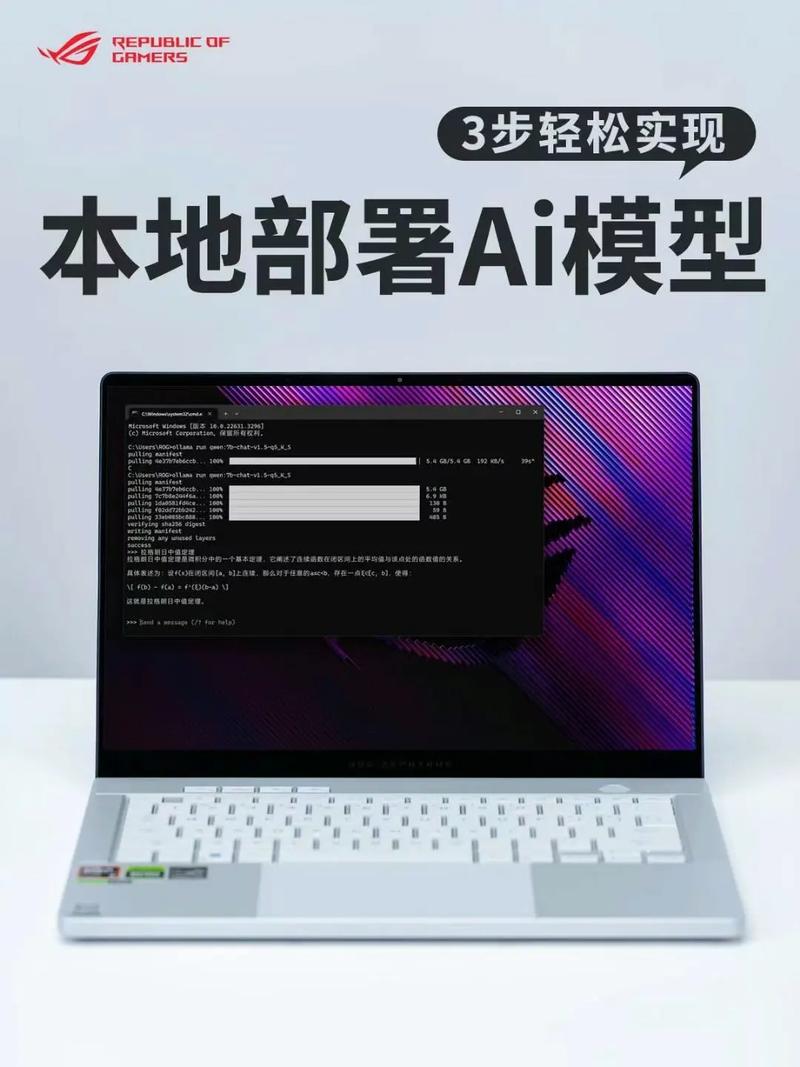
要开始构建本地AI模型,第一步是选择合适的模型类型,市面上有许多开源模型可供选择,如大型语言模型(LLM)或计算机视觉模型,对于初学者,我推荐从轻量级模型入手,比如Hugging Face提供的Transformer模型,这些模型易于下载和集成,确定模型后,需评估硬件需求,本地运行AI模型通常需要较强的计算资源:建议至少配备多核CPU、8GB以上RAM,以及支持CUDA的NVIDIA GPU(如RTX 3060或更高),如果你的设备配置较低,可以考虑使用模型优化技术,如量化或剪枝,来降低资源消耗,量化能将模型大小压缩一半,使其在普通笔记本电脑上流畅运行。
软件环境搭建是关键环节,你需要安装必要的工具和框架,TensorFlow和PyTorch是两大主流选择,它们提供了丰富的库和社区支持,安装过程通常很简单:通过Python的pip命令安装框架,再添加依赖库如NumPy和Pandas,确保系统安装了最新版本的Python(推荐Python 3.8或更高),一个实用技巧是先创建虚拟环境,避免依赖冲突,使用conda或venv创建隔离空间,然后安装所需包,之后,下载预训练模型,许多平台如Hugging Face Hub提供免费模型下载,只需几行代码即可完成,通过Transformers库,你可以轻松加载一个LLM模型,并进行推理测试。

模型下载后,运行推理是核心步骤,这涉及编写简单脚本,输入数据让模型生成输出,以文本生成为例,你可以用Python脚本调用模型,处理本地文件或实时输入,调试过程中,可能遇到常见问题如内存不足或速度慢,这时,优化技巧很实用:启用GPU加速、使用批处理减少调用次数,或调整模型参数,设置最大生成长度来限制资源使用,初次运行可能耗时较长,但通过迭代优化,性能会显著提升,如果模型表现不佳,尝试微调:用本地数据集重新训练模型部分层,这能增强针对性和准确性,微调不需要海量数据,几百条样本就足够,工具如FastAI能简化过程。
安全性和维护是本地AI模型的重要方面,运行本地模型时,确保操作系统和软件定期更新,防止安全漏洞,数据隐私是最大优势,所有处理都在设备内部完成,避免云服务的数据传输风险,模型文件本身可能占用大量存储空间,建议定期清理缓存并使用压缩工具,监控资源使用情况,避免设备过热或性能下降,一个常见误区是认为本地AI复杂难懂,其实借助社区论坛和教程,如GitHub上的开源项目,你能快速找到解决方案。
从我的角度看,本地AI模型代表了一种趋势:技术民主化,它让个人和小型企业不再受限于大公司云服务,赋予用户更多自主权,随着硬件成本下降和开源生态繁荣,本地AI将更易普及,我们可以期待更多高效模型出现,使本地部署成为标准做法,拥抱这一变化,不仅能提升技能,还能为创新开辟新路径,实践是最好的老师,动手尝试会让你收获满满。

 13888888888
13888888888

 点击咨询
点击咨询 