人工智能技术的快速发展让个人开发者也能轻松接触到前沿的AI模型,无论是生成创意文本、处理图像,还是分析数据,运行AI模型已不再是大型企业的专利,本文将用通俗易懂的方式,带你了解个人如何从零开始跑通一个AI模型,并规避常见误区。
第一步:明确目标与资源评估
在动手前,先问自己两个问题:“我需要解决什么问题?”和“我能投入多少资源?”

- 问题定义:AI模型种类繁多,例如图像识别、文本生成、数据预测等,若目标是生成文案,可考虑GPT类模型;若需要识别图片中的物体,则更适合卷积神经网络(CNN)。
- 资源评估:包括硬件(电脑配置、是否支持GPU)、时间(模型训练周期)和预算(是否使用付费云服务),训练一个基础图像分类模型,若使用CPU可能需要数小时,而GPU可缩短至几分钟。
关键建议:优先选择轻量级框架(如TensorFlow Lite、PyTorch Mobile)或直接调用API(如Hugging Face的模型库),降低本地部署门槛。
第二步:选择开发工具与环境
个人开发者常用的工具有两类:本地环境与云端平台。
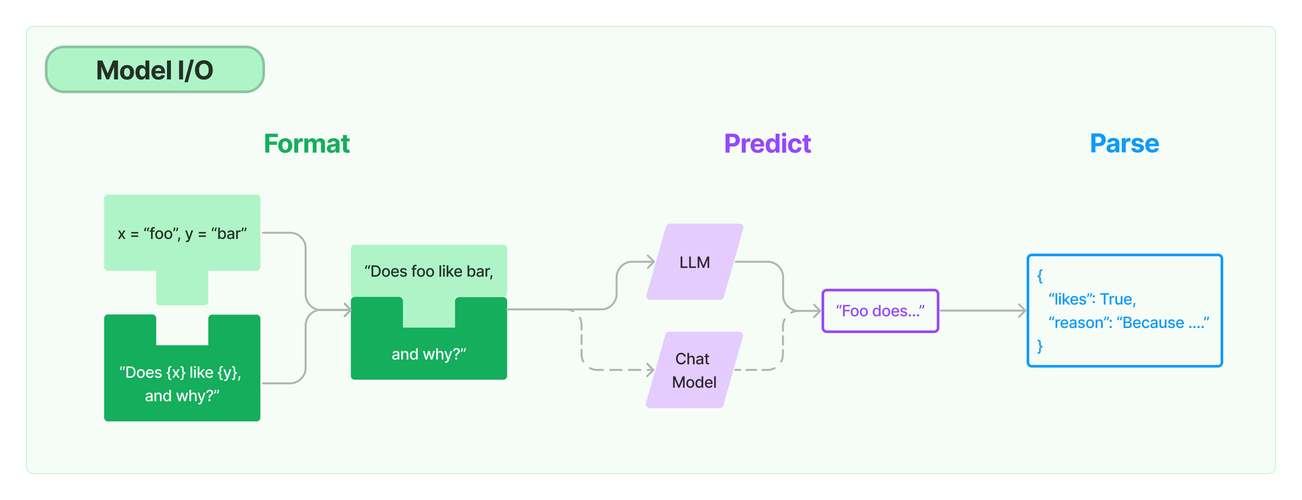
- 本地环境:适合小规模实验,推荐安装Anaconda管理Python环境,搭配Jupyter Notebook编写代码,若电脑配置较低,可优先运行优化后的预训练模型(如MobileNet)。
- 云端平台:Google Colab和Kaggle Kernel提供免费GPU资源,适合需要高性能计算的场景,在Colab中加载Hugging Face的Transformer库,10分钟内即可完成一个文本生成模型的微调。
避坑指南:避免盲目追求最新框架,Stable Diffusion虽火,但对显存要求极高;初学者可从Keras或FastAI入手,简化代码复杂度。
第三步:数据准备与预处理
数据是AI模型的“燃料”,质量直接影响结果。

- 数据收集:开源平台(Kaggle、UCI数据集)提供大量标注数据,若需自定义数据,可用爬虫工具(如Scrapy)或手动标注(借助LabelImg等工具)。
- 数据清洗:删除重复、缺失或噪声数据,训练一个情感分析模型时,需统一文本格式(去除特殊符号、统一大小写)。
- 数据增强:针对图像数据,可通过旋转、裁剪、调整亮度增加样本多样性;文本数据则可使用同义词替换、句子重组。
注意:个人使用需确保数据来源合法,避免侵犯隐私或版权。
第四步:模型训练与调优
- 选择预训练模型:90%的案例无需从头训练,Hugging Face、PyTorch Hub等平台提供可直接调用的模型,用ResNet-50快速实现图像分类,仅需替换最后的全连接层。
- 超参数设置:学习率、批次大小(Batch Size)和迭代次数(Epoch)需反复调试,初始阶段可使用自动调参工具(如Keras Tuner)节省时间。
- 评估指标:分类问题看准确率、精确率;生成任务可参考BLEU分数或人工评估,若模型过拟合(训练集表现好,测试集差),需增加Dropout层或扩充数据。
高效技巧:训练时开启早停(Early Stopping),避免无效计算;使用混合精度训练(FP16)加速GPU运算。
第五步:部署与应用
模型训练完成后,需转化为实际应用。
- 本地部署:将模型导出为ONNX或TensorFlow SavedModel格式,通过Flask或FastAPI搭建简易API接口。
- 移动端适配:使用TensorFlow Lite将模型压缩,部署到手机或嵌入式设备,在安卓应用中集成图像分类功能。
- 持续优化:监控模型在实际场景中的表现,定期用新数据微调(Fine-tuning)。
案例:个人开发者常将AI模型用于自动化办公(如邮件分类)、自媒体内容生成(视频字幕提取)或智能家居控制(语音指令识别)。
常见问题与误区
- 盲目追求大模型:GPT-4虽强大,但个人设备难以承载,7B参数以下的模型(如Llama 2)更易跑通。
- 忽略算力成本:训练一个10层的神经网络,若在云端按小时计费,可能超出预算,建议先估算成本(如AWS的Calculator工具)。
- 缺乏迭代思维:AI模型需多次优化,首次训练准确率60%并不可怕,通过调整数据或模型结构可逐步提升。

 13888888888
13888888888

 点击咨询
点击咨询 