人工智能技术正逐步渗透到各个领域,掌握构建AI模型的能力已成为数字化时代的重要技能,本文将从零开始拆解构建AI模型的完整流程,帮助技术爱好者跨越理论与实践的门槛。
第一步:明确应用场景与技术路线
成功的AI项目始于精准的场景定位,建议采用四象限分析法:横轴标注业务价值与实现难度,纵轴标注数据可获得性与技术成熟度,例如智能客服系统属于高业务价值、中等技术难度的典型场景,根据Gartner最新技术成熟度曲线,优先选择处于"稳步爬升期"的技术方案。
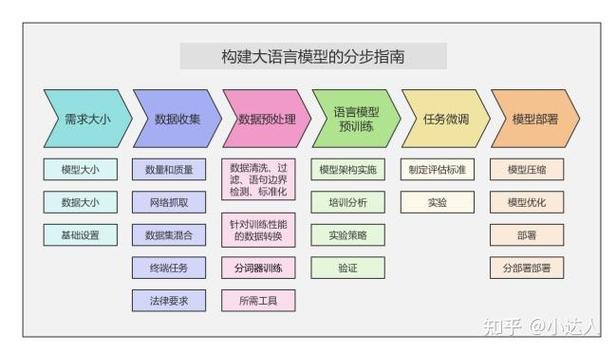
第二步:构建数据工程体系
数据质量直接影响模型效果,需建立数据生命周期管理系统,收集阶段建议采用混合采样策略,对结构化数据使用分层抽样,非结构化数据采用聚类抽样,清洗环节重点关注缺失值处理,对连续变量使用KNN插补法,分类变量采用多重插补法,特征工程方面,时序数据推荐使用TSFRESH自动特征生成工具,文本数据可采用BERT嵌入表示。
技术栈选择指南
- 开发框架:TensorFlow适合生产部署,PyTorch利于研究迭代
- 计算资源:NVIDIA T4显卡支持中小规模训练,A100适合大型模型
- 部署工具:ONNX实现跨平台部署,TensorRT优化推理速度
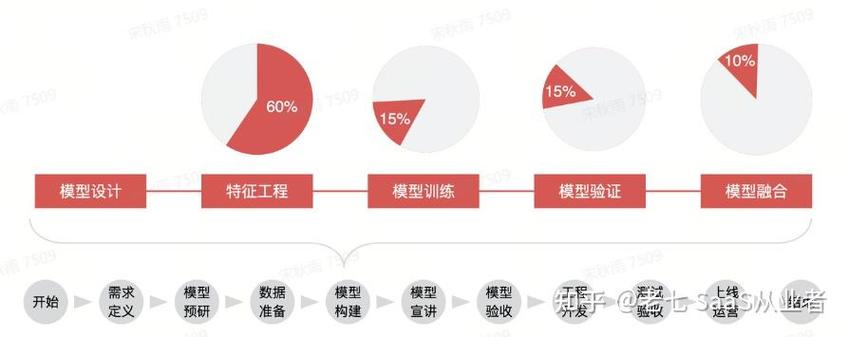
第三步:模型架构设计与训练
在图像识别场景,ResNet-50仍是基准模型的首选,其残差结构能有效缓解梯度消失,自然语言处理任务中,BERT-base模型通过预训练机制可快速适配下游任务,训练过程中建议采用混合精度训练,配合学习率余弦退火策略,可提升20%训练速度。
调参技巧与评估体系
建立三维评估体系:准确率关注预测精度,F1-score平衡类别偏差,AUC-ROC评估整体区分能力,超参数优化推荐使用Optuna框架,其TPE算法比传统网格搜索效率提升5倍以上,为防止过拟合,可引入早停机制与权重惩罚项,当验证集损失连续3个epoch未下降时自动终止训练。
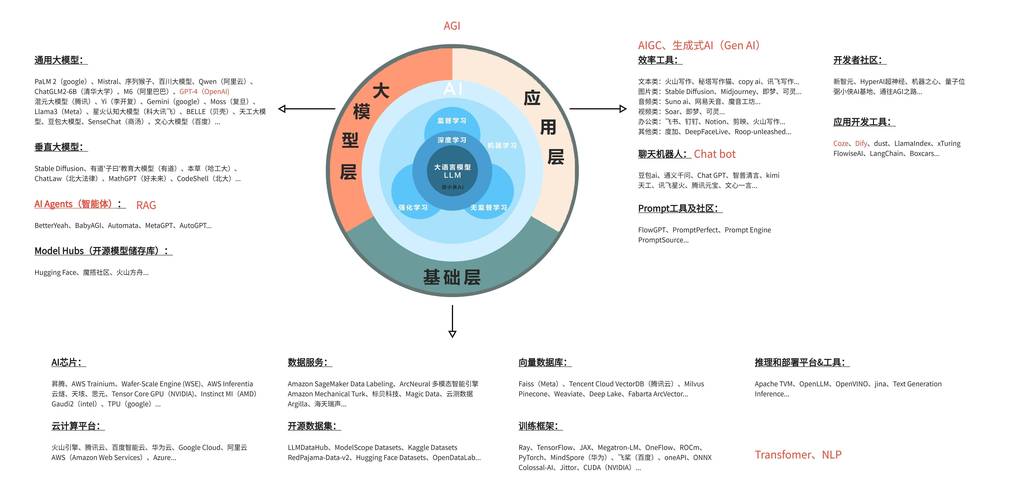
第四步:模型部署与监控
将训练好的模型转换为TorchScript格式,通过Flask搭建REST API接口,生产环境需部署模型版本控制系统,使用Prometheus+Granfana构建监控看板,实时跟踪QPS、响应延迟等关键指标,建立模型漂移检测机制,当输入数据分布偏移超过预设阈值时触发重新训练。
持续优化策略
建立AB测试框架,新模型需通过显著性检验方可上线,采用知识蒸馏技术,将大模型能力迁移至轻量级模型,定期更新训练数据,保持数据分布与真实场景的一致性,建议每季度进行一次模型健康度评估,从预测准确性、运算效率、资源消耗三个维度进行综合评分。
人工智能模型的构建是系统工程,需要技术能力与工程思维的结合,从业者应保持对Mlops技术演进的关注,在模型可解释性、联邦学习等前沿领域持续探索,当技术方案能切实解决业务痛点时,AI才能真正创造价值。

 13888888888
13888888888

 点击咨询
点击咨询 