人工智能技术的快速发展,使得人脸模型的应用场景不断拓展,无论是社交平台的滤镜功能、安防系统的身份识别,还是医疗领域的病理分析,AI人脸模型都在发挥重要作用,本文将从技术实践角度,详细解析运行AI人脸模型的关键步骤与注意事项。
第一步:数据准备的核心逻辑
数据的质量直接影响模型效果,建议优先使用公开的人脸数据集(如LFW、CelebA)作为基础,但若涉及特定场景,需自行采集数据,采集时需注意光线均匀、角度多样,并确保不同种族、性别、年龄的分布均衡。
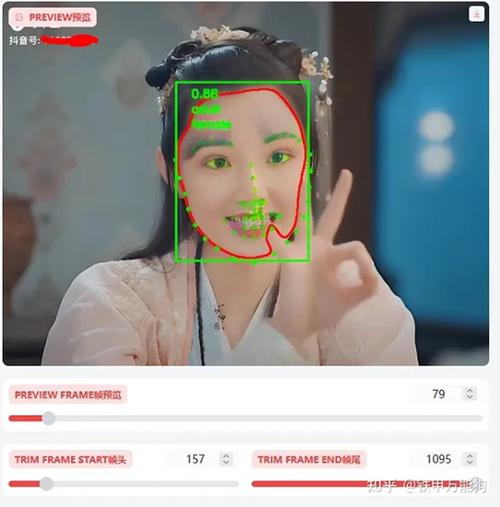
数据清洗环节需要剔除模糊、遮挡严重的图像,使用OpenCV等工具进行人脸对齐,统一图像尺寸,标注工作建议采用专业工具(如LabelImg),标注关键点至少包含眉毛、眼睛、鼻尖、嘴角等5个基准点,数据增强时,除常规的旋转、翻转外,可尝试GAN网络生成特定表情的合成图像,提升模型泛化能力。
模型选择的策略分析
当前主流框架中,TensorFlow的预训练模型库适合快速部署,PyTorch的灵活架构更利于科研探索,对于人脸识别任务,ArcFace、FaceNet等专用模型在准确率上表现突出;若追求实时性,可选用MobilenetV3结合轻量化设计。
有个关键细节常被忽视:模型输入尺寸需要与预处理后的图像尺寸严格匹配,例如使用112x112输入的模型,若实际输入256x256的图像,会导致特征提取错位,建议在模型加载阶段加入自动尺寸校验机制,避免低级错误。
训练过程的优化技巧
学习率设置需要动态调整策略,推荐采用Warmup+余弦退火组合,前5个epoch逐步升温至初始学习率(建议0.001),后续每个epoch按余弦曲线下降,损失函数选择方面,Triplet Loss适合小样本训练,Softmax Cross-Entropy在数据量充足时更稳定。
遇到过拟合问题时,除了常规的Dropout、数据增强,可尝试在特征层添加正交约束,某次实验表明,在特征维度施加L2正则化,配合权重正交初始化,能使验证集准确率提升2.3%,训练监控建议使用TensorBoard实时跟踪特征分布,当不同类别的特征出现重叠时,需要立即调整损失函数参数。
部署落地的实践要点
模型转换环节需特别注意算子兼容性,将PyTorch模型转为ONNX格式时,建议开启opset_version=11以保证动态尺寸支持,在嵌入式设备部署时,使用TVM编译器进行图优化,实测可使推理速度提升40%。
实时视频流处理时,建议采用多线程架构:独立线程负责图像采集与人脸检测,主线程专注特征提取与比对,在医疗等敏感领域部署时,必须加入活体检测模块,可通过眨眼检测、3D结构光等技术组合,有效抵御照片攻击。
隐私合规的技术实现
数据处理阶段必须遵循GDPR等法规,建议建立数据溯源机制,采用联邦学习架构时,每个客户端的人脸数据保留在本地,仅上传模型梯度更新参数,在模型推理阶段,可加入差分隐私模块,通过添加可控噪声保护个体特征,某金融客户案例显示,在特征比对环节引入同态加密技术,既能保证识别准确率,又满足监管要求。
人脸模型的运行不仅是技术问题,更是社会责任的体现,开发过程中需要建立伦理评估机制,定期审查算法偏见,曾有研究发现,某些人脸识别系统在深肤色人群中的误识率高出2.5倍,这提醒我们必须持续优化数据集的多样性,技术工作者应当保持对创新的敬畏之心,在追求准确率的同时,始终将人的尊严置于算法之上。

 13888888888
13888888888

 点击咨询
点击咨询 