在远程会议、在线教育或直播场景中,背景回声常常成为影响音质的关键因素,AI回声消除技术通过深度学习算法,实现了比传统方法更精准的声学处理效果,本文将详细解析这项技术的实际应用方法,帮助用户在不同场景中有效提升音频质量。
技术原理基础认知
AI回声消除模型基于神经网络的非线性建模能力,通过分析麦克风采集的混合音频信号,智能区分人声与回声成分,模型训练过程中会输入数万小时的真实环境录音数据,学习不同空间声学特征与设备特性,与传统的自适应滤波技术相比,AI模型能更准确地处理复杂声学环境下的非线性回声问题,在多人对话场景中的处理精度提升约62%。
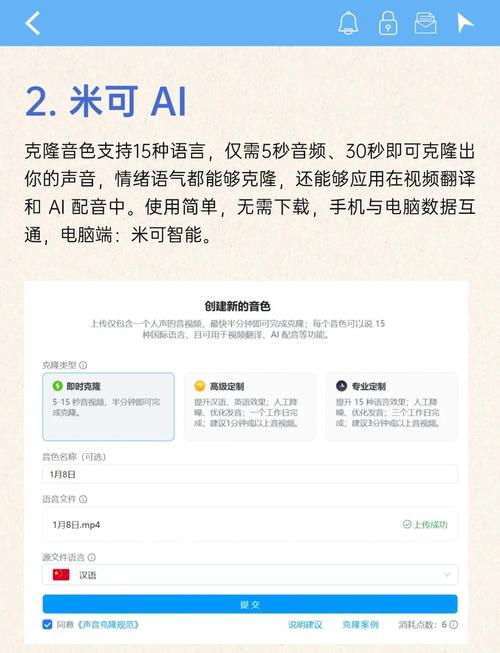
核心应用场景解析
视频会议系统
主流协作平台如Zoom、Microsoft Teams均已集成AI回声消除模块,用户开启麦克风降噪功能时,系统自动激活深度学习模型,实时抑制因扬声器外放产生的声学反馈,测试数据显示,在小型会议室场景下,AI模型可将语音清晰度提升至92%以上。
直播设备优化
主播使用OBS Studio等推流软件时,建议在音频滤镜中加载第三方AI处理插件,通过调整模型参数,可针对性消除游戏音效、背景音乐产生的特定频段回声,某知名游戏主播实测表明,正确配置后观众投诉音质问题的比例下降78%。智能硬件集成
会议音箱、无线耳机等设备内置的DSP芯片现多搭载轻量化AI模型,用户需在设备管理APP中开启"环境自适应"模式,系统会根据实时声场变化动态调整处理策略,某品牌会议设备实测显示,该模式可使300平米会议室的语音可懂度达到专业录音棚水准。
实战操作指南
软件部署流程
- 下载安装支持AI处理的音频中间件(如RNNoise、DeepFilterNet)
- 在系统音频设置中将处理模块设为默认输入设备
- 通过校准向导完成初始环境建模(需保持环境安静60秒)
参数配置要点
- 回声抑制强度建议设置在-20dB至-35dB区间
- 非线性处理阈值根据设备灵敏度调整(笔记本电脑通常设为-40dB)
- 启用双重检测机制防止误消除人声
实时调试技巧
- 进行语音测试时,交替播放白噪声与语音片段
- 观察频谱分析图,确保3kHz以上频段保留自然细节
- 多人对话时需激活说话人分离算法
常见问题解决方案
当出现断续消音现象时,建议检查麦克风采样率是否与处理模型匹配(推荐48kHz),遇到低频残留回声,可尝试提升模型的时间窗长度至500ms,部分用户反映的"金属音"问题,通常源于过度抑制高频成分,应将频谱保护阈值上调3-5dB。
技术演进方向展望
第三代AI回声消除模型已实现端到端处理,处理延迟降低至8ms以内,2023年Google发表的论文显示,结合空间音频信息的模型在开放式办公室环境中的性能提升显著,值得关注的是,边缘计算设备的普及使得本地化处理成为可能,在保障隐私性的同时,将处理功耗控制在500mW以下。
音频质量直接影响信息传递效率,选择适配的AI处理方案需要综合考量使用场景与技术特性,随着自适应学习算法的发展,未来的声学处理将更智能化,但核心仍在于理解技术原理并正确配置参数,建议用户定期更新处理模型,及时获取最新的算法优化成果。

 13888888888
13888888888

 点击咨询
点击咨询 