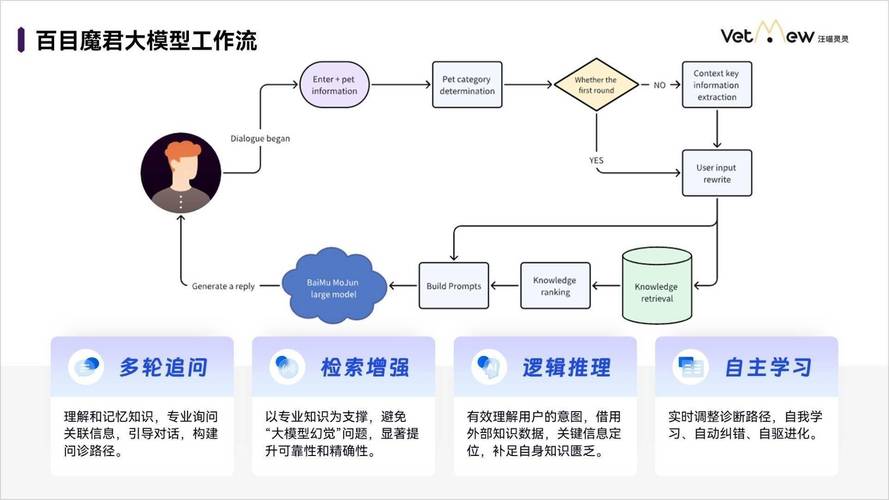
理解AI模型切换的核心逻辑
AI模型的切换是技术应用中常见的需求,尤其在处理不同任务或优化性能时,无论是开发人员还是普通用户,掌握切换模型的方法能显著提升工作效率,本文将从实际场景出发,解析切换AI模型的关键步骤与注意事项,帮助读者快速掌握这一技能。
为什么需要切换AI模型?
AI模型的性能与适用场景密切相关,自然语言处理任务可能需要GPT系列模型,而图像识别可能更适合ResNet或YOLO架构,切换模型的常见原因包括:
- 任务适配性:不同任务对模型的精度、速度、资源消耗要求不同。
- 技术迭代:新模型可能具备更高的准确率或更低的计算成本。
- 资源优化:根据硬件条件(如GPU内存)选择轻量级或复杂模型。
明确需求是切换模型的第一步,需结合具体目标权衡模型的优缺点。
切换前的准备工作
-
确认技术兼容性

- 检查当前框架(如TensorFlow、PyTorch)是否支持目标模型,部分模型需特定版本的依赖库,需提前安装或升级。
- 验证硬件配置是否满足新模型的要求,大模型可能需要更高显存或分布式计算支持。
-
数据与环境的备份
- 切换模型可能导致原有代码或数据格式不兼容,建议备份训练数据、配置文件及关键代码。
- 使用虚拟环境(如conda或docker)隔离实验环境,避免影响现有项目运行。
-
选择合适的替代模型
- 通过开源社区(如Hugging Face、GitHub)或学术论文获取模型信息,优先选择经过广泛验证的成熟方案。
- 对候选模型进行基准测试,对比其精度、推理速度及内存占用。
切换模型的详细步骤
步骤1:卸载旧模型并清理依赖
若旧模型通过包管理工具安装(如pip),需彻底卸载相关库,避免版本冲突。
pip uninstall torch pip cache purge # 清理残留文件
步骤2:部署新模型框架
- 从官方渠道下载模型文件(.pt、.h5等格式)或通过API调用云端模型(如OpenAI接口)。
- 若使用预训练模型,需加载对应的权重文件和配置文件,以PyTorch为例:
import torch model = torch.hub.load('pytorch/vision', 'resnet50', pretrained=True)
步骤3:适配数据输入与输出格式
- 检查新模型的输入维度(如图像尺寸、文本长度),调整数据预处理流程。
- 修改后处理代码,例如分类任务需根据新模型的类别标签重新映射结果。
步骤4:验证与调试
- 使用测试数据集运行推理,确保输出符合预期。
- 监控资源占用情况(可使用nvidia-smi或htop工具),优化批次大小或模型量化参数。
常见问题与解决方案
-
依赖冲突导致运行报错
使用虚拟环境重新安装依赖库,或通过工具(如pipenv)锁定版本。
-
新模型推理速度过慢
- 启用模型剪枝、量化或转换为ONNX格式以加速推理。
- 检查是否启用GPU加速,部分框架需手动设置设备类型。
-
精度显著下降
- 确认训练数据的分布是否与新模型匹配,必要时进行微调(fine-tuning)。
- 检查预处理步骤(如归一化参数)是否与模型训练时一致。
个人观点:技术选择需平衡实用性与前瞻性
模型切换不仅是技术操作,更是资源分配的决策,过度追求最新模型可能导致开发周期延长,而坚守旧架构可能错失性能红利,建议团队建立模型评估机制,定期审查技术栈,结合业务需求制定迭代计划,在实时性要求高的场景中,轻量级模型(如MobileNet)可能是更优解;而在数据量充足的离线任务中,复杂模型(如Transformer)的潜力更大。
技术决策者应关注行业动态,但避免盲目跟风,通过小规模实验验证可行性,再逐步推广到生产环境,才能在效率与稳定性之间找到最佳平衡点。

 13888888888
13888888888

 点击咨询
点击咨询 