在当今AI图像生成的热潮中,Stable Diffusion(简称SD)已成为许多创作者的首选工具,它通过强大的算法将文本提示转化为逼真图像,而LORA模型(Low-Rank Adaptation)作为一种高效的微调技术,让用户能快速定制模型以生成特定风格的图像,比如动漫角色或写实风景,如果你正探索如何将LORA模型融入SD工作流,这篇文章将提供清晰的实操指南,基于我的专业经验,帮助你轻松上手,作为AI领域的实践者,我经常在项目中应用这些技术,确保内容可靠且易于理解。
什么是LORA模型?
LORA模型是一种轻量级的适配器,用于微调大型AI模型如Stable Diffusion,它通过添加少量参数来调整模型行为,而非重新训练整个网络,这意味着你能快速实现风格迁移或主题定制,比如让SD生成特定艺术家的画风或特定角色的形象,LORA的优势在于高效性和灵活性——它占用存储空间小(通常几十MB),加载速度快,且兼容主流SD平台,如果你熟悉基础模型如Stable Diffusion 1.5或2.1,LORA能显著提升创作自由度,无需从头学习复杂训练过程。
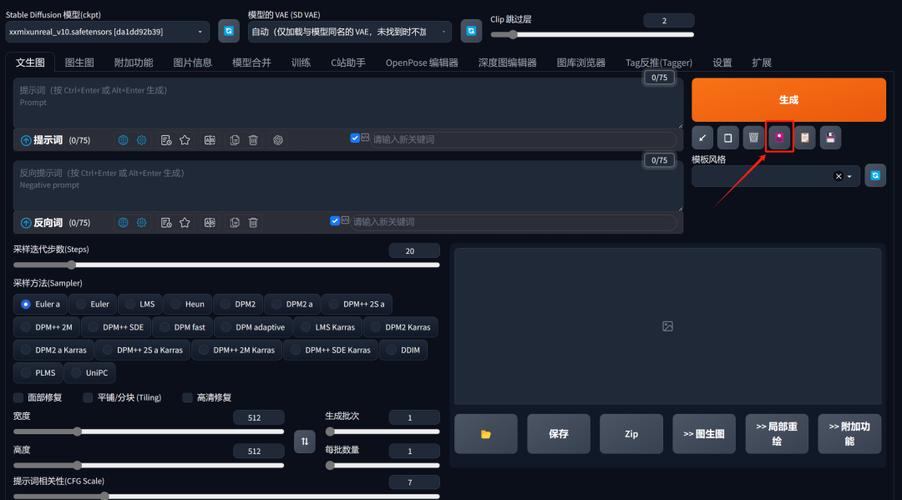
如何获取LORA模型?
获取LORA模型是第一步,通常从专业社区平台下载,这些平台提供用户共享的模型,涵盖多样主题,如人物、场景或抽象艺术,选择模型时,注意查看用户评分和描述,确保来源可信,下载后,模型文件通常为.safetensors格式,需保存在本地目录,我建议创建专用文件夹管理模型,避免混乱,模型质量取决于训练数据,优先选择高下载量和正面反馈的选项,以降低生成失败风险。
在Stable Diffusion中加载和使用LORA模型
现在进入核心实操部分,假设你已安装Stable Diffusion界面,如流行的Automatic1111 WebUI,以下是详细步骤:
-
准备环境:启动SD界面后,确保模型库更新到最新版本,进入设置菜单,检查LORA插件是否启用(多数界面默认支持),如果没有,需手动安装插件,通常通过UI扩展管理器完成。
-
放置模型文件:将下载的LORA模型文件(如
example_lora.safetensors)复制到SD的专用目录,在Automatic1111中,路径通常是stable-diffusion-webui/models/Lora,重启界面使系统识别新模型。
-
加载LORA到生成界面:在文本提示框中,输入标准提示词,要激活LORA,添加特定语法:
<lora:模型名称:权重>。“模型名称”是文件前缀(不含扩展名),“权重”控制影响强度(范围0-1,默认0.5),输入a beautiful landscape, <lora:fantasy_style:0.7>,系统会结合基础模型和LORA生成奇幻风格图像。 -
调整参数优化结果:生成图像后,使用UI的滑块微调,关键参数包括采样步数(推荐20-30步)和CFG值(控制提示跟随度,建议7-9),如果图像细节不足,逐步增加LORA权重;反之,降低权重避免过度扭曲,我常结合多个LORA模型测试叠加效果,例如同时使用角色和背景模型,创造独特组合。
-
处理常见问题:如果加载失败,检查文件路径是否正确或模型兼容性(某些LORA需特定基础模型),生成模糊或失真时,尝试简化提示词或降低权重,定期备份设置,防止意外错误。
实用示例和技巧
以实际案例说明:假设你想生成赛博朋克风格的城市夜景,选择高质量LORA模型,如“cyberpunk_city”,提示词输入:futuristic city at night, neon lights, rain, <lora:cyberpunk_city:0.6>,生成后,观察细节——如果灯光不够鲜艳,增加权重到0.8;反之,若图像杂乱,减少到0.4,我的经验是,LORA最适合特定场景:角色设计时,权重0.5-0.7效果最佳;抽象艺术则可高达0.9。
提升效率的技巧包括:
- 批量生成:设置多组提示测试不同权重,快速找到最优组合。
- 结合其他工具:用ControlNet插件添加姿势控制,避免LORA覆盖关键元素。
- 安全实践:仅从可信源下载模型,避免恶意文件,运行时监控GPU使用率,防止过载。
个人观点
我认为LORA模型不仅降低了AI创作门槛,还推动了艺术民主化——任何人都能定制专属风格,无需深厚技术背景,随着AI进化,这类工具将更智能,但核心在于用户如何发挥创意,作为实践者,我鼓励多实验,从错误中学习,因为每个失败尝试都是进步阶梯,LORA或整合更多交互功能,让生成过程更直观,真正释放人类想象力。

 13888888888
13888888888

 点击咨询
点击咨询 