在人工智能技术快速迭代的今天,大型语言模型已成为推动行业变革的核心引擎,从医疗诊断到金融决策,从创意生成到客户服务,这些具备千亿级参数的智能系统正通过持续学习重塑人类的生产方式,本文将深入解析大模型训练的核心逻辑与技术路径,为读者呈现人工智能进化的底层脉络。
数据工程:智能系统的基石
训练大型模型的第一步是构建高质量数据生态,以国际知名研究机构为例,其团队需从公开文献、专业数据库、多语种互联网内容中筛选超万亿字符的原始素材,数据处理团队采用语义聚类算法剔除重复信息,通过知识图谱技术识别跨领域关联,并引入语言学专家对20%的样本进行人工校验,特别在医疗等专业领域,数据清洗需结合领域知识库,确保专业术语与临床指南的精确对应。
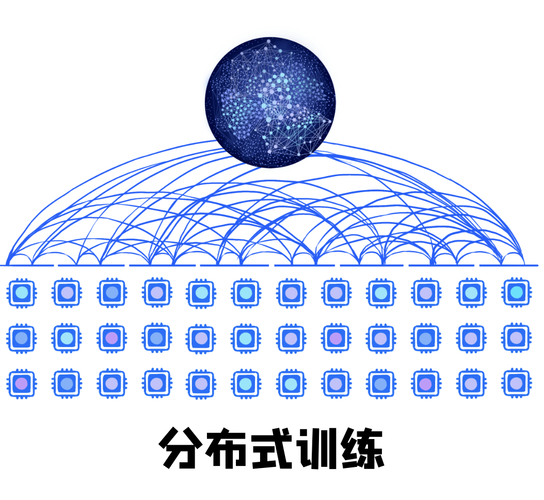
架构创新:算力与算法的交响
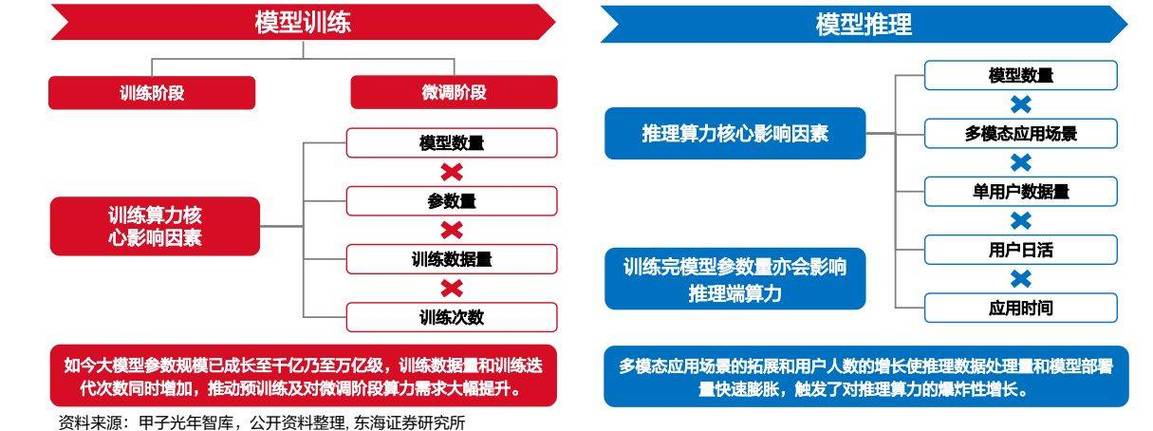
Transformer架构的并行计算特性为模型进化提供了可能,工程师团队采用混合专家系统(MoE),将整体参数划分为多个功能模块,每个子网络专注特定类型任务,在硬件层面,分布式训练框架将计算任务拆解到超过万块GPU组成的集群,通过3D并行策略实现计算、数据、流水线三个维度的优化,某科技企业在训练13B参数模型时,通过动态梯度裁剪技术将训练稳定性提升40%,同时采用混合精度计算节省15%的显存占用。
训练策略:智能涌现的关键
预训练阶段采用自监督学习机制,模型通过完形填空式的任务理解语言内在规律,某实验室记录显示,当模型参数突破百亿级时,系统突然展现出跨任务迁移能力,这种现象被学界称为"智能涌现",在微调阶段,人类反馈强化学习(RLHF)机制引入价值对齐模块,工程师通过百万量级的人类偏好数据,训练奖励模型来引导生成内容符合伦理规范,值得注意的是,最新研究采用课程学习策略,让模型从简单任务逐步过渡到复杂场景,相比传统方法提升训练效率28%。
优化艺术:平衡性能与成本
面对千亿参数模型的巨大能耗,创新者正在探索更可持续的路径,知识蒸馏技术将大模型能力迁移至小参数模型,某案例显示,经过优化的7B模型在特定任务上可达到原始模型96%的效能,量化压缩方案通过降低参数精度减少存储需求,结合动态稀疏计算,使模型推理速度提升3倍,行业领先企业已开始部署自适应计算框架,根据任务复杂度动态调整激活参数量,实现能效比的最优化。
当我们在医疗领域看到AI系统准确解读医学影像,在科研前线目睹模型提出创新假设,这些突破本质上都是海量数据、先进算法与计算工程深度融合的产物,模型训练已从单纯的技术实践演变为需要跨学科协作的系统工程,在这个过程中,持续创新与伦理考量始终是推动技术向善的双轨,未来的智能进化,必将建立在更高效的学习范式与更严谨的价值体系之上。

 13888888888
13888888888

 点击咨询
点击咨询 