明确训练目标与场景需求
训练模型前,需清晰定义大饼AI的应用场景,是用于图像识别(如检测大饼的烘烤程度),还是数据分析(如预测销量趋势)?目标的明确直接影响数据采集方向与模型架构选择。
- 案例参考:若目标是识别大饼的缺陷,需优先收集包含不同缺陷状态的图像数据,而非泛化的食品图片。
- 关键问题:模型的输出形式是什么?是否需要实时响应?这些因素决定了计算资源分配与算法复杂度。
数据采集与预处理
数据是模型训练的基石,大饼AI的独特性要求数据必须贴合实际场景。

- 数据来源
- 使用传感器采集物理参数(如温度、湿度);
- 通过摄像头获取图像或视频数据;
- 整合历史业务数据(如销售记录、用户反馈)。
- 数据清洗
- 剔除重复、噪声数据(如模糊图像或异常温度记录);
- 标注需精准:标注“焦糊”的图片需由专业烘焙师确认。
- 数据增强
- 对图像数据进行旋转、裁剪、调整亮度,提升模型泛化能力;
- 对数值型数据做归一化处理,避免量纲差异影响训练效果。
模型选择与架构设计
根据任务类型选择合适的算法框架:
- 图像类任务:卷积神经网络(CNN)仍是主流,可尝试ResNet、EfficientNet等预训练模型进行迁移学习;
- 时序数据分析:LSTM、Transformer架构更适合处理销量预测或生产流程优化问题;
- 轻量化需求:若需部署到边缘设备(如烤箱内置AI),可选用MobileNet或量化剪枝技术压缩模型体积。
注意事项:
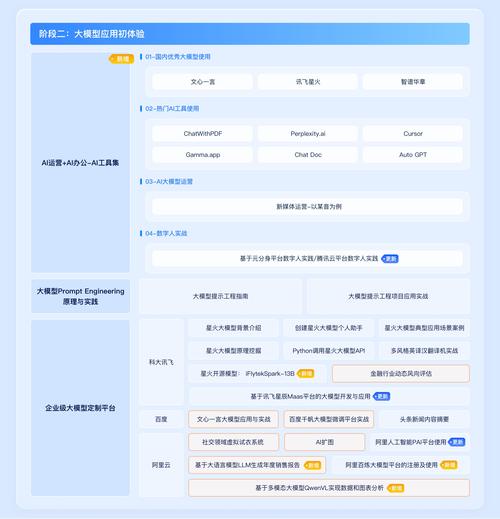
- 避免盲目追求复杂模型,优先验证基础模型的效果;
- 结合业务需求调整输出层,例如分类任务需设定阈值,回归任务需定义误差范围。
训练过程的核心技巧
- 划分数据集
按7:2:1的比例分配训练集、验证集与测试集,确保模型未见过测试数据,避免过拟合。 - 超参数调优
- 学习率:初始值建议设为0.001,根据损失曲线动态调整;
- 批量大小(Batch Size):硬件允许下,较大批量可提升训练稳定性;
- 早停法(Early Stopping):当验证集损失连续3轮未下降时终止训练,节省算力。
- 评估指标
- 分类任务:关注精确率、召回率、F1值;
- 回归任务:使用均方误差(MSE)或平均绝对误差(MAE)。
模型优化与迭代
训练完成后,需通过以下步骤提升实用性:
- 错误分析
统计模型在测试集中的错误样本,针对性补充数据或调整特征提取逻辑,若模型将“轻微开裂”误判为正常,需增加此类样本的权重。 - A/B测试
将新旧模型并行运行,对比实际场景中的效果差异,如识别准确率提升是否带来成本下降。 - 持续学习
建立数据回流机制,定期用新数据微调模型,适应环境变化(如烤箱设备升级导致图像特征改变)。
避开常见误区
- 误区1:数据越多越好
低质量数据反而干扰模型学习,10万张标注精准的图片,远胜100万张未清洗的杂乱数据。 - 误区2:过度依赖自动化工具
自动调参工具(如AutoML)虽能节省时间,但缺乏领域知识的干预可能导致模型偏离业务逻辑。 - 误区3:忽视部署环境
训练时的高性能GPU环境与部署时的嵌入式设备算力差异巨大,需提前测试推理速度。
未来趋势与个人观点
随着AI技术的发展,大饼AI的模型训练将更注重多模态融合(如结合图像与传感器数据联合分析)和可解释性(例如通过热力图展示模型判断依据),个人认为,垂直领域的AI落地需平衡技术先进性与实用性——与其追求“最前沿的算法”,不如深耕场景理解,构建从数据到决策的闭环,真正有效的模型,往往是那些能精准解决一个小问题,而非泛泛覆盖多个领域的“万能工具”。

 13888888888
13888888888

 点击咨询
点击咨询 