当AI模型多到难以选择时,普通人该如何应对?
近年来,人工智能技术发展迅猛,各类AI模型层出不穷,从语言大模型到图像生成工具,从行业专用算法到开源社区项目,技术的迭代速度远超普通用户的认知能力,面对琳琅满目的选择,许多用户陷入困惑:如何从海量模型中挑选适合自己的工具?如何在有限资源下高效利用这些技术?本文将围绕这一痛点,提供可落地的解决思路。

模型泛滥的背后:技术发展的双刃剑
AI模型的爆发式增长,本质上是技术开源化、应用场景细分化以及资本推动的共同结果,以自然语言处理领域为例,仅过去三年,全球就诞生了超过200个公开可用的语言模型,涵盖通用对话、代码生成、数据分析等垂直方向,这种繁荣固然加速了技术进步,但也带来了三大现实问题:
- 选择成本过高
普通用户缺乏专业能力辨别不同模型的差异,往往依赖宣传资料或他人推荐,导致试错成本激增。 - 资源重复浪费
企业可能因盲目追逐新模型而重复采购功能重叠的工具,造成算力、资金与人力投入的损耗。 - 应用门槛提升
开发者需要不断学习新框架,业务团队则面临工具链频繁切换的适应压力。
破解困境的核心:建立筛选与管理框架
第一步:明确需求优先级
在接触任何AI模型前,需先回答三个问题:
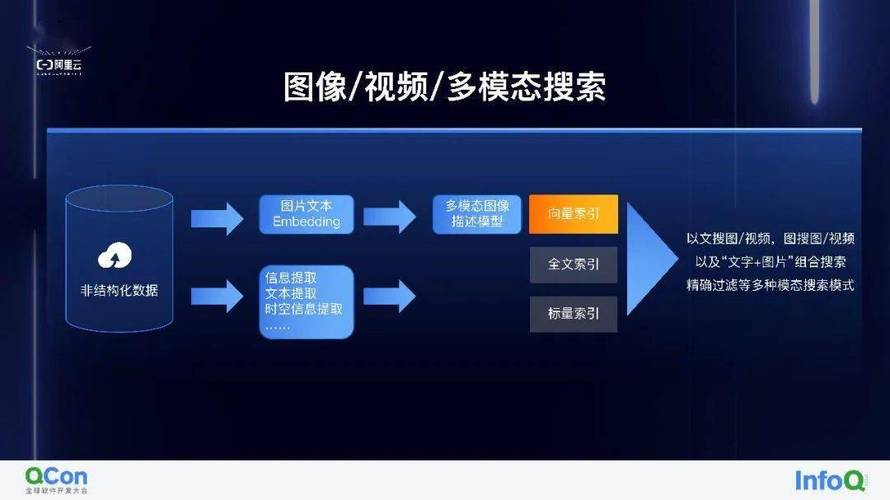
- 核心目标:需要解决的具体问题是什么?(自动化客服、数据分析预测)
- 资源边界:可投入的预算、算力及技术团队能力上限在哪里?
- 合规要求:数据隐私、行业监管等限制条件有哪些?
通过需求清单排除90%的非必要选项,中小型企业若仅需基础文本生成功能,完全无需追逐千亿参数级的大模型。
第二步:评估模型的“性价比”
从四个维度建立评估矩阵:
- 性能指标:准确率、响应速度、泛化能力(可用公开测试集验证)
- 部署成本:本地化部署难度、API调用费用、硬件兼容性
- 生态支持:社区活跃度、文档完整性、故障响应机制
- 长期价值:供应商技术路线图、模型更新频率
建议用“二分法”快速决策:将候选模型分为“必须满足”和“加分项”两类,优先满足刚性需求。
第三步:建立资源管理机制
- 统一接口层:通过中间件整合不同模型的API,降低系统耦合度
- 动态监控看板:实时追踪各模型的使用率、成本消耗与效果反馈
- 定期清理规则:设定“末位淘汰”机制,停用低效或重复的工具
某电商公司的实践显示,通过上述方法,其AI工具数量从47个精简至12个,年度成本下降58%,而业务指标未受影响。
普通用户的高效生存指南
善用聚合平台
国内外已有平台对主流AI模型进行横向评测(如Papers With Code、Model Zoo),提供性能对比、应用案例及部署教程,普通用户可将其作为“决策导航”,避免从零开始研究。
关注“场景工具箱”
与其追逐最新模型,不如深耕垂直领域。 创作者:聚焦图文生成类工具链(AIGC+排版优化+版权检测)
- 数据分析师:构建从数据清洗到可视化的一站式分析流水线
警惕技术泡沫
部分厂商会通过夸大参数规模制造营销噱头,需牢记:模型的最终价值=实际效果×落地可行性,某金融团队曾测试过某万亿参数模型,发现其业务场景中的表现反而弱于百亿参数的精调版本。
行业观察:未来的进化方向
当前AI模型发展呈现两大趋势:
- 轻量化与专业化并存
边缘计算推动模型小型化(如MobileNet、TinyBERT);医疗、法律等领域出现高度定制化模型。 - 开源生态重构竞争格局
Hugging Face等平台通过标准化接口降低使用门槛,使中小企业能快速组合最佳技术方案。
Gartner预测,到2026年,80%的企业将采用“模型组装”策略,而非单一供应商绑定,这意味着选择能力本身正在成为核心竞争力。
个人观点
面对AI模型的爆炸式增长,被动等待技术成熟已非明智之举,无论是企业还是个人,都需要建立“技术策展人”思维——不追求占有所有工具,而是围绕自身需求构建敏捷的技术组合,正如一位资深工程师的感悟:“用好三个精心挑选的模型,远胜过盲目收集三十个用不上的‘神器’。” 在这个算力过剩而注意力稀缺的时代,精准的减法比贪婪的加法更能创造价值。

 13888888888
13888888888

 点击咨询
点击咨询 