人工智能技术已渗透到各个领域,从医疗诊断到自动驾驶,从金融风控到智能客服,AI模型正改变着人类社会的运行方式,对于初次接触AI技术开发的从业者而言,掌握模型训练的核心逻辑比单纯使用工具更重要,本文将系统解析AI模型训练的完整流程与关键技术要点。
数据质量决定模型上限 训练数据的品质直接影响模型最终表现,2019年MIT的研究表明,高质量数据集能使模型准确率提升27%-35%,数据采集需遵循三个原则:相关性、代表性和多样性,以电商推荐系统为例,需包含用户行为数据、商品特征数据、上下文环境数据等多维度信息。

数据清洗环节要处理缺失值、异常值和重复值,对于文本数据,需进行分词、去除停用词、词干提取等预处理;图像数据则需统一尺寸、标准化像素值、进行数据增强,特别要注意样本分布的均衡性,医疗影像识别场景中,若正常样本占比90%,需通过过采样或合成数据技术平衡正负样本。
模型架构的科学选择 选择模型架构需考虑任务类型与数据特性,卷积神经网络(CNN)在图像处理领域表现优异,Transformer架构在自然语言处理中占据主导地位,实际应用中常采用迁移学习策略,如在ImageNet预训练的ResNet模型基础上,通过微调(Fine-tuning)适应特定分类任务。
参数初始化直接影响训练效率,Xavier初始化方法能保持各层激活值的方差稳定,He初始化更适合ReLU激活函数,学习率设置需要动态调整策略,余弦退火(Cosine Annealing)或周期性重启(Cyclical Learning Rate)能有效避免局部最优。
训练过程的精细调控 批量大小(Batch Size)的设定需平衡内存消耗与梯度稳定性,混合精度训练可将显存占用降低40%,同时保持模型精度,正则化技术的合理应用至关重要,Dropout率通常设置在0.2-0.5之间,L2正则化系数需通过网格搜索确定。
损失函数的选择要与任务目标严格对应,分类任务常用交叉熵损失,目标检测多用Smooth L1 Loss,生成对抗网络(GAN)则需要设计特殊的对抗损失,多任务学习时,需通过不确定性加权法平衡不同任务的损失贡献。
模型评估与持续优化 评估指标必须与业务目标对齐,分类问题不能仅看准确率,需综合考量精确率、召回率、F1值,推荐系统要关注AUC和NDCG指标,目标检测需计算mAP值,交叉验证(Cross-Validation)是验证模型泛化能力的金标准,k-fold策略能有效利用有限数据。
模型压缩技术在实际部署中不可或缺,知识蒸馏(Knowledge Distillation)可将大模型能力迁移到轻量级网络,参数量化(Quantization)能在精度损失可控的前提下将模型体积压缩4倍,持续学习(Continual Learning)机制使模型能适应数据分布的动态变化,弹性权重固化(EWC)算法能有效缓解灾难性遗忘问题。
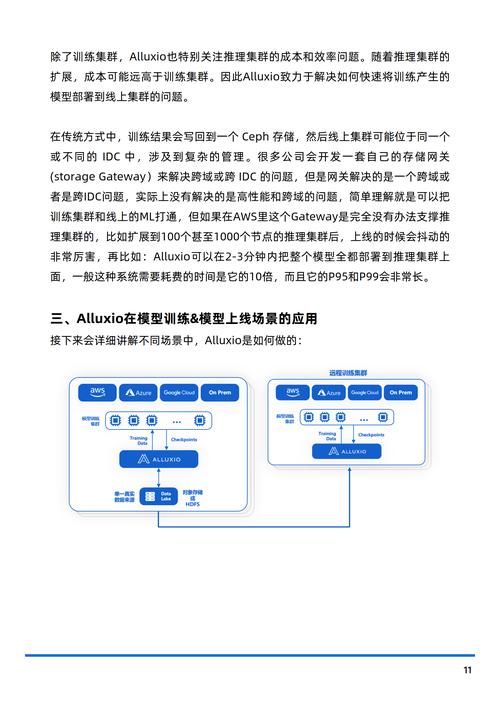
工程实践的注意事项 训练环境搭建要考虑硬件适配性,GPU集群需配置NCCL通信库实现高效并行,版本控制不仅要管理代码,还要记录超参数配置和数据集版本,模型监控系统应包含资源使用率、训练曲线可视化、异常检测等功能模块。
伦理风险防范不容忽视,人脸识别模型需进行偏见检测,自然语言模型要设置内容过滤机制,欧盟AI法案要求高风险系统必须保留完整的可追溯记录,这要求训练日志包含数据来源、处理步骤、验证结果等完整信息。
AI模型训练是系统工程,需要算法理解、工程能力和领域知识的深度融合,从数据准备到模型部署,每个环节都需要科学决策与严谨验证,随着AutoML技术的发展,部分环节可实现自动化,但工程师的创造性思维仍是推动技术进步的核心动力,在实际项目中,建议建立标准化的训练流程文档,持续积累领域专属的模型库和工具集,这将显著提升团队的技术迭代效率。

 13888888888
13888888888

 点击咨询
点击咨询 