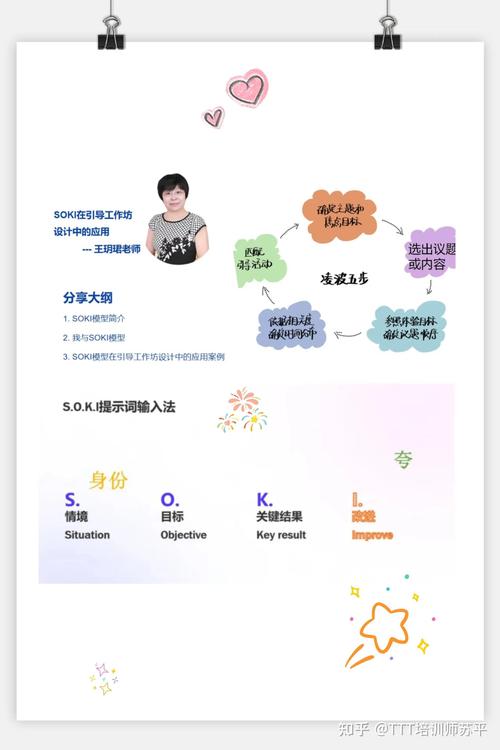
AI模型如何添加文字内容
在数字技术快速发展的今天,AI模型的应用已渗透到内容生产的各个环节,无论是生成文案、自动回复,还是创作故事,AI的文字处理能力正逐步改变传统内容生产方式,但对于许多刚接触AI技术的用户来说,如何让模型准确“添加文字内容”仍存在诸多疑问,本文将围绕技术原理、实现步骤、应用场景及常见问题,深入解析AI模型处理文字内容的核心逻辑。
AI模型添加文字内容的技术基础
AI模型添加文字内容的核心能力来源于自然语言处理(NLP)技术,通过深度学习算法,模型能够理解上下文、分析语义,并生成符合逻辑的文本,以下是实现这一过程的三大技术模块:
-
语言理解与上下文建模
AI模型通过预训练学习海量文本数据,掌握语法规则、词汇关联及语义逻辑,GPT系列模型通过Transformer架构捕捉长距离依赖关系,从而理解用户输入的意图,当用户要求“在段落中插入描述气候的句子”时,模型会根据上下文判断需要补充的内容类型及风格。
-
生成策略与约束控制 的添加并非完全随机,开发者可通过设置参数控制生成结果,
- 温度值(Temperature):调整生成文本的随机性(低温度值生成确定性内容,高温度值更具创造性)。
- 关键词限制:指定必须包含的词汇,确保内容符合特定主题。
- 长度控制:限制生成文本的字符数或段落数。
-
后处理与质量校验 后,需通过规则过滤或人工审核确保准确性,使用正则表达式剔除敏感词,或通过二次模型检测逻辑矛盾。
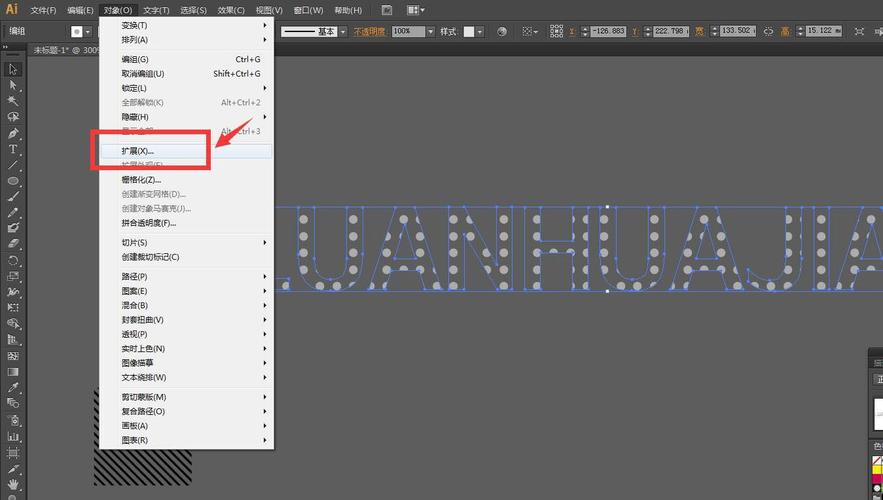
实现AI模型添加文字内容的步骤
若需将AI模型集成到实际应用中,需遵循以下流程:
数据准备与预处理
- 领域适配:根据应用场景(如电商、教育、新闻)收集相关文本数据,增强模型的垂直领域知识。
- 清洗与标注:去除噪声数据(如乱码、重复内容),并对关键信息(如实体、情感倾向)进行标注,提升模型理解能力。
模型选择与微调
- 开源模型 vs. 自研模型:
通用场景可选用GPT-3、ChatGLM等成熟模型;垂直领域建议基于开源架构(如Hugging Face的Transformer库)进行微调。 - 微调方法:
使用领域数据对模型进行增量训练,调整超参数(如学习率、批次大小),使其适应特定任务。
接口部署与交互设计
- API封装:将模型部署为RESTful API,便于与其他系统(如CMS、客服平台)集成。
- 用户交互优化:设计清晰的输入提示(Prompt),请在第2段插入一句关于产品优势的说明”,降低用户使用门槛。
持续迭代与反馈机制
- 收集用户对生成内容的评分或修改建议,用于模型再训练。
- 监控生成内容的多样性,避免模型陷入固定模板化输出。
典型应用场景与案例分析
场景1:自动化内容编辑
- 案例:新闻网站需在已有报道中补充背景信息,通过输入原文及指令“加入事件历史背景”,AI可自动检索相关知识库并生成连贯段落。
- 优势:节省人工查阅资料时间,提升内容信息密度。
场景2:个性化内容生成
- 案例:电商平台为不同用户生成定制化商品描述,基于用户浏览记录,AI在通用文案中添加“适合您的肤质”“与您购买过的A产品搭配使用”等个性化语句。
- 优势:提升转化率,增强用户体验。
场景3:多语言内容扩展
- 案例:企业官网需将中文产品介绍同步翻译为英文,并添加本地化表达,AI模型可先完成翻译,再根据目标市场文化插入符合语境的内容。
- 挑战:需解决文化差异导致的语义偏差问题(如成语、俚语)。
常见问题与解决方案
问题1:生成内容偏离主题
- 原因:输入指令模糊或训练数据噪声过多。
- 解决:优化Prompt设计(如明确指定“添加3句关于环保技术的描述”);增加领域数据微调比例。
问题2:文本逻辑不连贯
- 原因:模型上下文窗口限制或训练不足。
- 解决:采用分块处理策略,将长文本分段输入;引入强化学习奖励机制,优先保留高逻辑连贯性的输出。
问题3:伦理与合规风险
- 风险点可能包含偏见、虚假信息。
- 规避措施过滤模型(如Perspective API);建立人工审核流程,尤其针对医疗、法律等高风险领域。
未来趋势与个人观点
随着多模态技术的融合,AI模型添加文字内容的能力将不再局限于纯文本环境,结合图像识别技术,模型可自动为图片生成注释,或根据视频内容添加解说词,技术的进步也需伴随伦理规范的完善——如何在“创造力”与“可控性”之间找到平衡,将是开发者长期面临的课题。
从实践角度看,AI模型并非替代人类创作者,而是作为效率工具释放生产力,对于内容生产者而言,重点应转向更高阶的任务:制定内容策略、把控质量标准、创新表达形式,唯有将AI的“精准执行”与人类的“创意洞察”结合,才能真正实现技术价值的最大化。

 13888888888
13888888888

 点击咨询
点击咨询 