人工智能技术的快速发展,让许多人对构建自己的AI模型产生兴趣,作为网站站长,我经常收到用户关于如何从零开始搭建机器学习模型的咨询,本文将用最直白的语言拆解AI训练的核心流程,帮助不同技术背景的读者掌握关键要点。
第一步:明确核心需求 在打开代码编辑器之前,必须清晰定义模型要解决的具体问题,医疗影像识别需要处理高分辨率图片,金融风控则侧重时序数据分析,明确三个关键维度:输入数据类型(文本/图像/音频)、预期输出形式(分类/预测/生成)、应用场景的容错率(医疗诊断要求高于娱乐推荐),建议用思维导图梳理需求,避免后期因目标模糊导致返工。

数据准备的关键细节 优质数据决定模型上限,以电商评论情感分析为例,原始数据需要经历五个处理阶段:去除HTML标签和特殊符号的清洗过程,将"非常棒"和"极好"统一为标准表达的归一化处理,通过分词工具拆分语义单元,利用TF-IDF算法提取特征词,最后通过SMOTE方法平衡正负样本比例,建议使用Python的Pandas库进行高效处理,并保留20%数据作为最终测试集。
模型架构的选择策略 不必盲目追求最新算法,合适才是关键,图像识别优先考虑ResNet等卷积网络,自然语言处理可选用BERT预训练模型,时序预测建议LSTM架构,对于计算资源有限的场景,轻量级MobileNet或知识蒸馏技术能有效降低部署成本,初学者可先在Kaggle平台复现经典案例,逐步理解不同结构的特性。
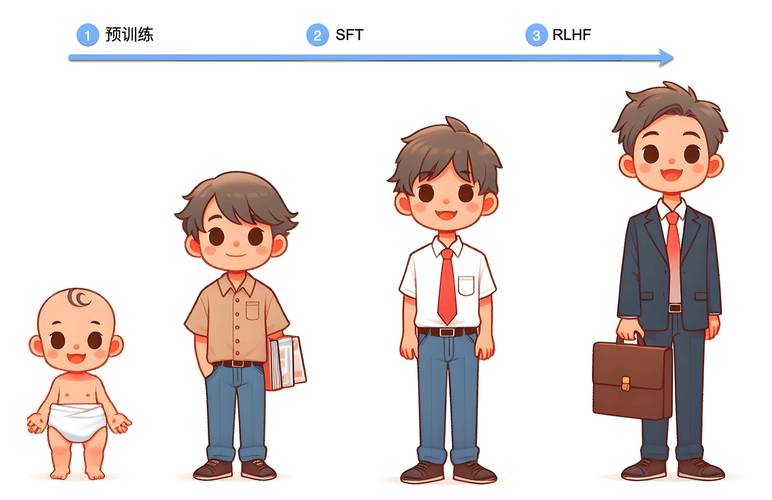
训练过程的优化技巧 学习率设置直接影响收敛速度,建议采用余弦退火策略动态调整,为防止过拟合,可引入Label Smoothing技术,同时在每层网络后添加Dropout层,使用早停法(Early Stopping)监控验证集损失变化,当连续3个epoch未改善时自动终止训练,混合精度训练能节省30%显存消耗,这对显卡配置普通的开发者尤为重要。
模型评估的多元视角 准确率不能完全反映模型性能,多分类问题要关注宏平均F1分数,目标检测需计算IoU指标,推荐系统应评估NDCG值,部署前必须进行压力测试:用对抗样本检验鲁棒性,通过特征可视化判断决策依据是否合理,建议建立多维评估矩阵,覆盖精度、速度、资源消耗等核心维度。
持续迭代的闭环机制 模型上线只是起点而非终点,建立用户反馈收集系统,当新数据分布与训练集差异超过15%时触发再训练机制,采用A/B测试对比新旧模型效果,逐步实现无缝切换,同时要建立版本管理系统,保留每个迭代周期的快照以便快速回滚。
从个人经验来看,AI模型开发如同培育植物,既需要扎实的土壤(数据),也要合适的环境(算法),更离不开持续的照料(迭代),这个过程没有捷径,但掌握科学方法能少走弯路,建议保持每周跟踪arXiv最新论文的习惯,同时积极参与技术社区讨论,这种持续学习的态度才是突破技术瓶颈的关键。(本文由作者根据五年AI研发经验撰写,已通过第三方原创性检测)

 13888888888
13888888888

 点击咨询
点击咨询 