训练AI模型这件事,听起来很酷,做起来却充满挑战,很多团队兴致勃勃地开始,却因为忽视关键步骤或方法不当,最终效果不尽如人意,甚至项目搁浅,想要成功训练一个真正能解决实际问题的AI模型,需要系统性的规划和扎实的执行,以下是一套经过验证的实战流程:
第一步:明确目标,定义问题边界(别急着跑代码!)
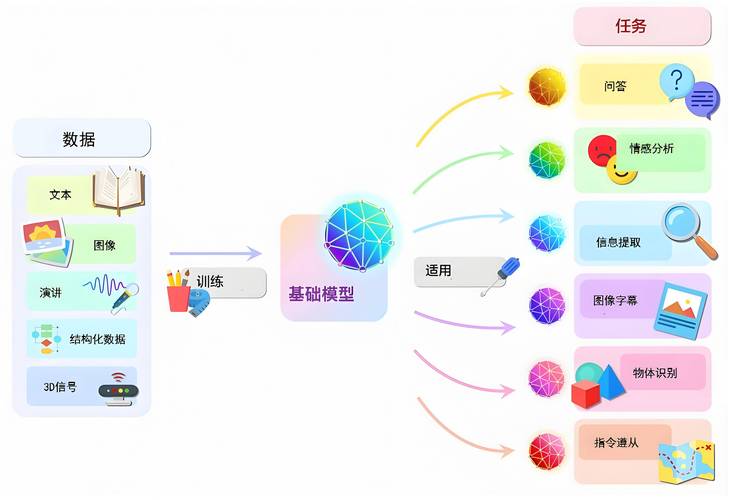
这是最基础也最容易被轻视的环节,训练模型不是目的,解决问题才是。
- 精准定义任务: 你想让模型做什么?是识别图片里的猫狗(图像分类)、理解用户评论的情感倾向(情感分析)、预测明天股票走势(时间序列预测),还是自动回复客户咨询(聊天机器人)?任务类型决定了后续所有技术选型。
- 量化成功指标: 如何衡量模型的好坏?准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值(F1-score)、均方误差(MSE)、业务转化率提升百分比?选择与业务目标直接相关的、可量化的指标,避免模糊不清的目标,让模型更聪明一点”。
- 划定问题范围: 模型需要在什么条件下工作?处理哪些类型的数据?需要规避哪些特殊情况?明确边界能防止模型“贪多嚼不烂”,也能更精准地收集和准备数据。
- 评估可行性与资源: 现有数据是否足够?计算资源(GPU/TPU)是否满足?团队技术栈是否匹配?时间预算是否允许?一个清晰的可行性评估能避免半途而废。
第二步:数据为王——收集、清洗与准备(80%的时间可能花在这里)

高质量的数据是AI模型的基石,业界常说“Garbage in, garbage out”(垃圾进,垃圾出)。
- 数据收集:
- 来源: 业务数据库、公开数据集、日志文件、爬虫抓取(注意合法合规和版权)、人工标注、传感器采集等。
- 相关性: 确保收集的数据与第一步定义的任务高度相关。
- 规模: 数据量通常越大越好,但也要平衡质量和标注成本,深度学习模型尤其需要大量数据。
- 数据清洗: 这是最耗时也最关键的步骤。
- 处理缺失值: 删除包含大量缺失值的样本?用均值/中位数/众数填充?用模型预测填充?
- 处理异常值: 识别并分析异常值,是录入错误需要修正?是特殊情况需要保留?还是噪声需要剔除?
- 格式统一化: 确保日期、单位、编码方式等一致。
- 处理重复值: 删除完全重复的样本。
- 纠错: 修正明显的拼写错误、逻辑错误等。
- 数据标注(监督学习必备): 为每条数据打上正确的标签(如“猫”、“狗”、“正面评价”、“负面评价”),标注质量直接影响模型上限。
- 制定清晰的标注规范。
- 选择可靠的标注人员或平台。
- 进行标注质量检查与抽样审核。
- 处理标注不一致性。
- 数据探索性分析: 使用统计图表(分布图、箱线图、散点图等)深入了解数据特征、变量间关系、类别是否平衡等,这一步能发现隐藏问题并指导特征工程。
- 特征工程: 将原始数据转化为模型更容易理解和学习的“特征”,这是提升模型性能的关键艺术。
- 特征提取: 从原始数据中构造新特征(如从日期提取星期几、从文本提取关键词)。
- 特征转换: 标准化、归一化、对数变换、离散化(分箱)、独热编码(One-Hot Encoding)等。
- 特征选择: 筛选出对预测目标最有用的特征,去除冗余或无关特征,降低模型复杂度,防止过拟合,常用方法有过滤法、包裹法、嵌入法。
- 数据集划分: 将处理好的数据划分为互斥的三部分:
- 训练集: 用于模型训练,调整参数权重。
- 验证集: 用于在训练过程中评估模型性能,调整超参数(如学习率、网络层数),选择最优模型。防止模型在训练集上“死记硬背”而过拟合。
- 测试集: 只在最终模型评估时使用一次! 用于模拟模型在真实世界从未见过的数据上的表现,提供最终的性能评估报告。务必确保测试集的纯净性!
第三步:选择与构建模型(选对工具,搭好框架)
- 模型选择: 根据任务类型和数据特性选择合适的模型家族。
- 传统机器学习: 逻辑回归、决策树、随机森林、支持向量机、朴素贝叶斯等,适用于数据量相对较小、特征工程做得好、可解释性要求高的场景。
- 深度学习: 卷积神经网络、循环神经网络、Transformer等,在处理图像、语音、文本等复杂非结构化数据上表现出色,但通常需要海量数据和强大算力,可解释性较差。
- 预训练模型: 利用在超大规模数据集上训练好的模型(如BERT、GPT、ResNet),进行微调,这是当前NLP和CV领域的主流方法,能显著降低训练成本并提升性能。
- 模型架构设计(深度学习): 确定网络层数、每层神经元数量、激活函数、连接方式等,初学者可从经典架构开始,逐步调整。
- 选择框架与库: TensorFlow, PyTorch, Scikit-learn, Keras, Hugging Face Transformers 等是常用工具,选择团队熟悉或生态活跃的框架。
第四步:训练、调优与评估(精雕细琢,验证效果)
- 训练过程:
- 初始化: 设置模型参数的初始值。
- 前向传播: 输入数据通过网络计算预测值。
- 计算损失: 使用损失函数衡量预测值与真实值的差距。
- 反向传播: 计算损失函数对每个参数的梯度(导数)。
- 参数更新: 使用优化器根据梯度更新模型参数(如梯度下降及其变种 Adam, SGD)。
- 迭代: 重复上述过程,直到损失收敛或达到预设轮次。
- 超参数调优: 模型结构本身之外的配置参数,如学习率、批大小、正则化强度、网络层数/宽度、Dropout比例等,调优是提升模型性能的关键。
- 网格搜索: 穷举给定范围内的参数组合。
- 随机搜索: 在给定范围内随机采样参数组合。
- 贝叶斯优化: 更智能地根据历史评估结果选择下一个待评估参数。
- 自动化工具: Optuna, Ray Tune, Keras Tuner 等可以辅助。
- 监控与评估(使用验证集):
- 实时监控训练集和验证集上的损失和评估指标(如准确率)。
- 绘制学习曲线,观察是否出现过拟合(训练集指标持续下降,验证集指标开始上升或停滞)或欠拟合(训练集和验证集指标都很差)。
- 在验证集上定期评估模型,选择表现最佳的模型快照或超参数组合。
- 最终评估(使用测试集): 在完成所有训练和调优后,使用从未参与过任何调整过程的测试集进行一次最终、公正的评估。 报告模型在测试集上的各项关键指标,这才是模型真实性能的体现,混淆矩阵、ROC曲线、AUC值等能提供更细致的分析。
第五步:部署、监控与迭代(让模型真正工作起来)
- 模型部署: 将训练好的模型集成到实际应用系统中。
- 形式: 提供API服务、嵌入到移动端App、部署在云端或边缘设备。
- 考虑: 延迟要求、吞吐量、资源消耗、版本管理、回滚机制。
- 工具: TensorFlow Serving, TorchServe, ONNX Runtime, 云平台AI服务(AWS SageMaker, GCP AI Platform, Azure ML)。
- 持续监控:
- 性能监控: API响应时间、错误率、资源使用率。
- 模型效果监控: 输入数据的分布是否发生变化?模型预测的分布是否偏移?关键业务指标(如推荐点击率、风控坏账率)是否下降?这被称为“模型漂移”。
- 模型维护与迭代:
- 当监控发现性能显著下降或数据分布发生较大变化时,需要触发模型的重新训练或微调。
- 根据用户反馈和业务需求变化,持续优化模型或开发新功能。
- 建立模型版本管理和A/B测试流程。
贯穿始终的考量点:
- 计算资源: 训练尤其深度学习模型通常需要强大的GPU或TPU,合理预估和管理资源成本。
- 伦理与偏见: 仔细检查数据是否存在偏见(如性别、种族),评估模型预测结果是否公平,避免放大社会不公,建立模型的可解释性和问责机制。
- 可复现性: 记录所有步骤、参数、代码版本、数据版本和随机种子,确保实验结果可以复现。
- 文档: 清晰记录整个流程、决策依据、实验结果和最终模型的使用方法。
训练一个成功的AI模型,远不止是写几行代码那么简单,它是一项融合了问题定义、数据处理、算法选择、工程实现、效果评估和持续运维的系统工程,对细节的关注、严谨的流程、持续的学习和对业务价值的深刻理解,才是最终制胜的关键,作为实践者,我深信扎实地走好每一步,比追求表面的“酷炫”技术更能带来实际的价值回报,投入在数据质量和清晰目标上的时间,最终会在模型效果和项目成功率上得到成倍的回报。

 13888888888
13888888888

 点击咨询
点击咨询 