在数字化浪潮中,人工智能技术正以前所未有的速度渗透到各行各业,对于许多企业和开发者而言,将训练好的AI模型部署到私有环境中,已成为保障数据安全、提升服务稳定性的关键需求,私有化部署不仅能够有效避免敏感数据外泄,还能根据实际业务需求灵活调整模型性能,实现更高效的资源利用。
明确部署目标与环境准备
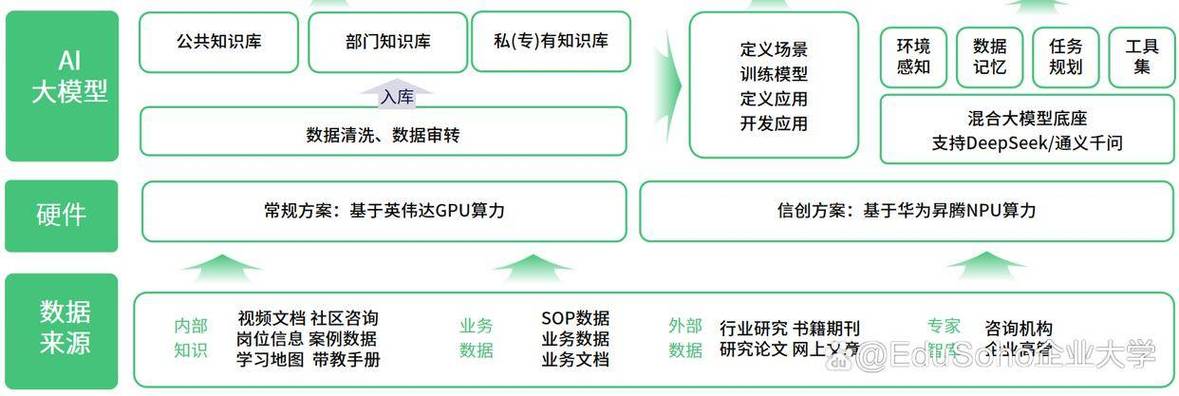
私有化部署的第一步是明确应用场景与性能要求,需根据模型的计算复杂度、预期访问量及响应速度等因素,选择合适的硬件设备或云服务器,CPU适用于轻量级推理任务,而GPU或NPU则更适合高并发、高精度的深度学习模型推理,需配置稳定的操作系统(如Linux)及必要的依赖环境,包括Python、Docker、CUDA等基础工具。
模型优化与封装
原始训练模型通常需经过优化才能适应生产环境,可通过模型剪枝、量化等技术减少计算量和存储空间,提升推理效率,随后,使用推理框架(如TensorFlow Serving、TorchServe或ONNX Runtime)将模型封装为标准化服务接口,支持HTTP/gRPC等通信协议,这一步骤确保了模型的可移植性和易用性。
安全性与权限管理
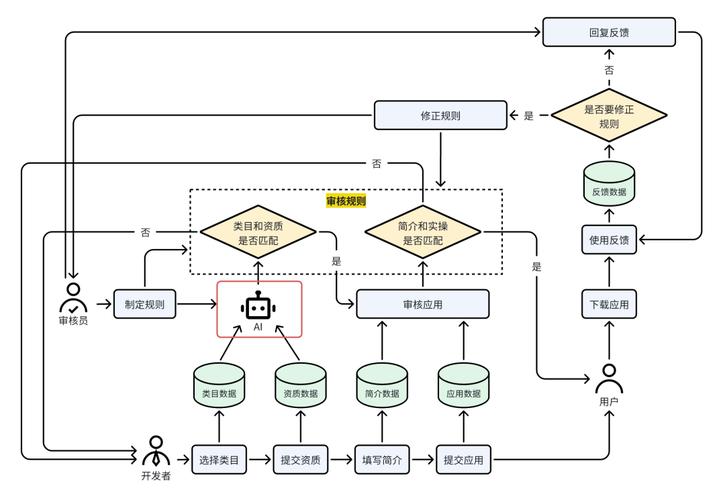
私有部署的核心优势在于数据自主可控,需通过防火墙规则、API密钥验证及访问控制列表(ACL)严格限制模型服务的访问权限,对于涉密数据,可额外采用端到端加密传输或联邦学习技术,进一步降低数据泄露风险,建议定期更新系统补丁与模型版本,防范潜在安全漏洞。
持续监控与性能调优
部署完成后需建立完善的监控体系,跟踪模型服务的响应延迟、吞吐量及错误率等关键指标,通过日志分析工具(如ELK stack)实时排查异常,并结合负载均衡机制动态分配算力资源,长期运行中,可根据实际反馈数据对模型进行增量训练或迭代优化,保持其预测准确性。
兼容性与扩展性设计
随着业务规模扩大,模型可能需适配多种硬件平台或操作系统,建议采用容器化技术(如Docker或Kubernetes)实现环境隔离与快速迁移,同时通过微服务架构将模型模块化,便于后续功能扩展或版本升级。
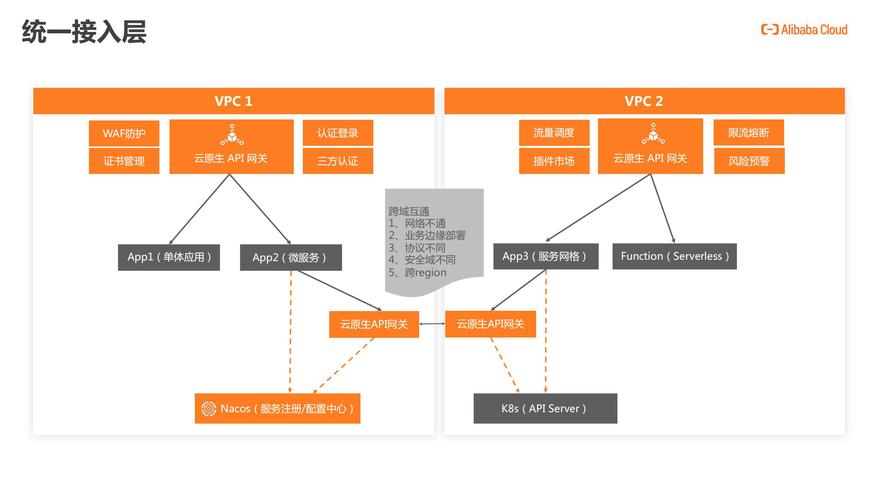
从技术层面看,私有化部署并非简单的环境迁移,而是涉及架构设计、资源调度与安全管理的系统工程,企业需结合自身技术储备与成本预算,选择适合的部署方案,对于中小型团队,可优先考虑基于开源框架的轻量级部署;而对大型企业,则可定制全栈式解决方案,实现更高程度的自动化运维。
随着边缘计算与隐私计算技术的成熟,模型私有化部署将更趋高效与普惠,它不仅是企业数据战略的重要支撑,也是推动AI技术真正落地于千行百业的关键一环。

 13888888888
13888888888

 点击咨询
点击咨询 