在人工智能技术快速发展的今天,LoRA模型作为一种高效的参数微调方法,正被越来越多的开发者和研究者所关注,其全称为“Low-Rank Adaptation”,即低秩适应,能够在保持预训练模型原有性能的基础上,以更少的计算资源和时间完成特定任务的适配,无论是自然语言处理、图像生成还是语音识别,LoRA都展现出显著的优势,本文将详细介绍如何使用LoRA模型,帮助初学者和有一定经验的用户更好地掌握这一技术。
要使用LoRA模型,首先需要理解其核心思想,传统的微调方法需要更新整个模型的参数,而LoRA通过引入低秩矩阵,仅对模型的一小部分参数进行调整,这种方式不仅大幅降低了计算成本,还能有效避免过拟合问题,在大型语言模型中,LoRA可以针对特定任务(如文本分类或对话生成)进行高效适配,而无需重新训练整个网络。
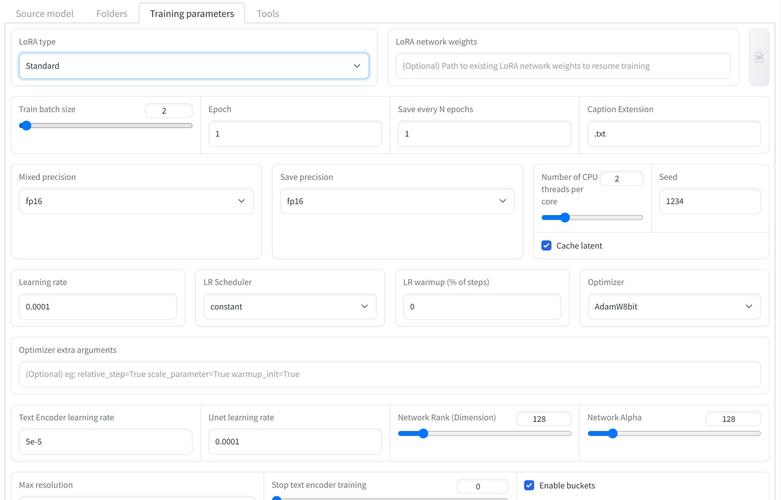
开始使用LoRA前,需确保具备基本的环境配置,需要安装Python及相关的深度学习框架,如PyTorch或TensorFlow,还需安装LoRA的实现库,例如Hugging Face的Transformers库,该库已集成LoRA支持,便于用户直接调用,建议使用GPU环境进行训练,以加速计算过程。
具体使用步骤可分为以下几个阶段:
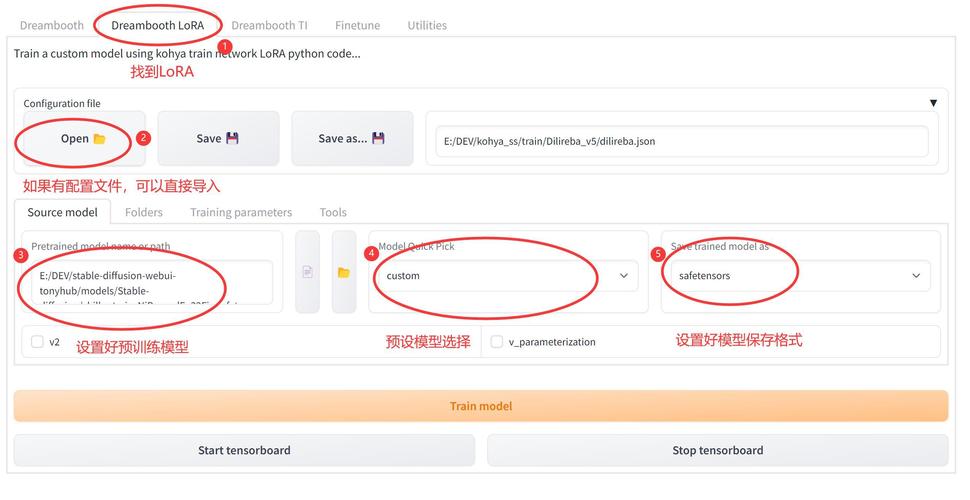
第一,数据准备,根据目标任务收集和整理数据集,若用于文本情感分析,需准备带有情感标签的文本数据,数据质量直接影响模型效果,因此需进行清洗和预处理,如去除噪声、统一格式等。
第二,选择基座模型,LoRA通常基于预训练模型(如BERT、GPT系列)进行微调,根据任务需求选择合适的模型,文本生成任务可选用GPT-3,图像任务可选择ViT等。
第三,配置LoRA参数,关键参数包括秩(rank)、缩放因子(scaling factor)和适配层(target layers),秩决定低秩矩阵的大小,一般取较小值(如4、8、16);缩放因子控制适配强度;适配层指定需微调的模型层,这些参数需根据任务复杂度调整,初学者可从默认值开始实验。
第四,训练模型,加载基座模型和LoRA配置,将训练数据输入模型进行微调,过程中需监控损失函数和准确率,避免过拟合,可使用早停(early stopping)或学习率调度(learning rate scheduling)优化训练。
第五,评估与部署,在验证集上测试模型性能,根据结果调整参数或数据,满意后,可将模型导出并部署到应用环境中,由于LoRA仅添加少量参数,部署便捷,无需大幅改动原有系统。
实际应用中,LoRA已广泛用于多个领域,在AI绘画中,LoRA可用于定制化风格生成,用户只需少量图像即可训练出专属模型;在智能客服中,LoRA能快速适配不同行业的对话需求,提升响应准确性,其低资源消耗的特性,尤其适合中小企业或个人开发者。
尽管LoRA优势明显,使用时仍需注意几点,参数设置需谨慎,过小的秩可能导致欠拟合,而过大会增加计算负担,基座模型的选择应与任务高度相关,否则影响微调效果,数据质量至关重要,需确保标注准确和代表性。
个人观点:LoRA技术无疑为AI应用落地提供了更高效的路径,其低资源特性降低了技术门槛,让更多创新想法得以实现,随着优化和普及,LoRA或将成为微调领域的标准方法之一,作为开发者,持续学习和实验是关键,只有深入理解原理并结合实际需求,才能充分发挥其潜力。

 13888888888
13888888888

 点击咨询
点击咨询 