训练人工智能模型编写代码是一项融合了计算机科学、数据工程和机器学习技术的复杂过程,它不仅需要高质量的数据和精妙的算法设计,更需要对软件开发本质的深刻理解,下面,我们将深入探讨这一过程的核心步骤与关键考量。
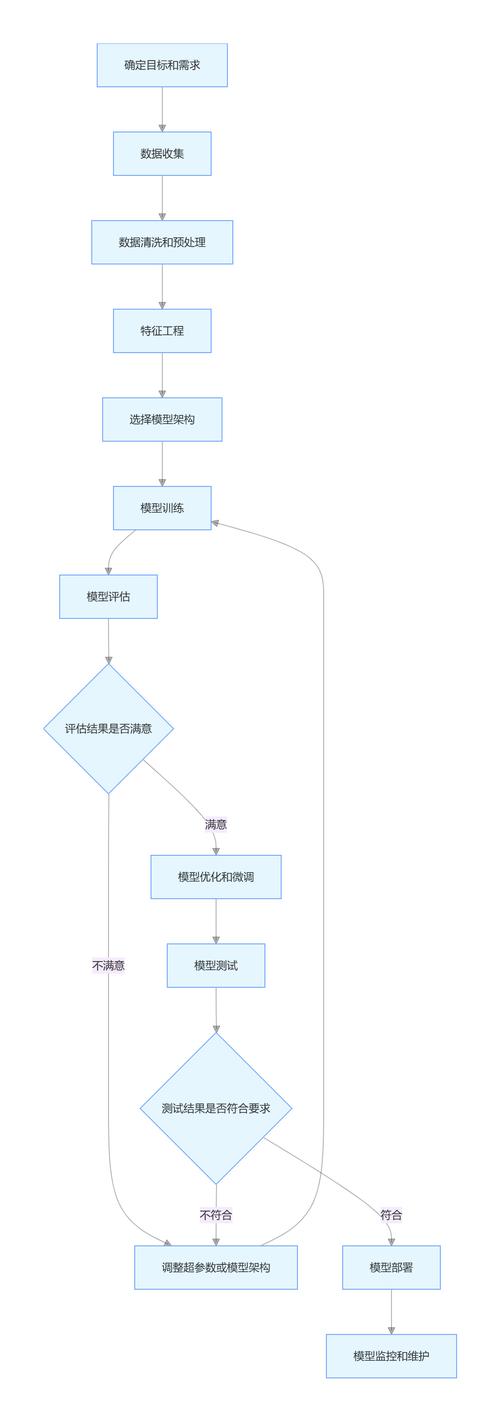
整个过程始于一个明确的目标定义,开发者必须精准定位希望模型完成的任务:是生成完整的函数,还是补全代码行?是进行不同编程语言间的转换,还是自动修复错误?定义的范围越清晰,后续的数据收集和模型训练就越有方向性,专门用于生成Python数据预处理代码的模型,与一个旨在完成全栈JavaScript开发的模型,其技术路径和所需资源截然不同。
数据是模型的基石,代码训练数据的质量直接决定了模型的性能上限,这些数据通常来源于公开的代码仓库(如GitHub)、开源项目以及经过精心整理的代码片段数据集,数据的预处理至关重要,需要经过清洗、去重、格式标准化,并确保不包含敏感信息或恶意代码,数据需要被标注,这种标注可能是隐性的,例如将代码本身作为标签,采用自监督学习;也可能是显性的,例如将代码和对应的自然语言描述配对,训练模型理解指令。
接下来是模型架构的选择,当前,基于Transformer架构的大语言模型(LLM)在此领域占据主导地位,这类模型通过其强大的注意力机制,能够有效捕捉代码中长距离的依赖关系,理解语法结构和逻辑上下文,开发者可以选择从零开始训练一个模型,这需要海量的计算资源和数据;更为常见的做法是采用预训练模型进行微调,预训练模型已经在海量文本和代码数据上学习了通用表示,通过使用特定领域的代码数据对其进行微调,可以高效地使其适应特定任务,例如专精于Solidity智能合约或SQL查询生成的模型。
训练过程本身是对模型参数的迭代优化,通过输入代码序列,模型不断预测下一个 token(可以是一个单词、一个子词或一个字符),并根据预测结果与真实数据之间的误差来调整内部参数,这个过程需要强大的算力支持,通常依赖GPU或TPU集群,训练中的关键超参数,如学习率、批次大小和训练轮数,都需要仔细调优,以避免欠拟合或过拟合现象,过拟合意味着模型只是机械记忆了训练数据,而无法泛化到未曾见过的新代码任务上。
评估与迭代是确保模型实用的关键环节,不能仅凭模型在训练数据上的表现来判断其优劣,必须使用一组未参与训练的真实代码案例来测试它,评估指标包括代码的编译通过率、功能正确性、执行效率以及代码风格的自然度,HumanEval等专门的代码基准测试集被广泛用于衡量模型的能力,根据测试结果,开发者需要回到前面的步骤,反思是数据质量不足、模型架构不合理还是训练策略有待改进,从而进行新一轮的迭代优化。
我们必须清醒认识到,AI编程助手是增强开发者能力的强大工具,而非替代品,它能够高效处理重复性模式代码,提供灵感启发,加速开发流程,但最终代码的逻辑正确性、安全性和架构合理性仍然需要人类工程师来把关,模型可能生成看似正确但存在细微漏洞或安全风险的代码,也可能无法完全理解复杂的、模糊的业务需求。
训练一个优秀的代码生成模型,是一场对数据质量、算法选择与工程实践能力的综合考验,它最终产出的不仅仅是一个模型,更是一套能够持续演进、不断学习的自动化开发辅助系统,它的价值在于与人协作,将开发者从繁琐的重复劳动中解放出来,从而更专注于更具创造性和战略性的核心问题。

 13888888888
13888888888

 点击咨询
点击咨询 