AI翻唱模型是当前数字音乐领域的一个创新应用,它利用人工智能技术模拟人类歌声,让用户能够生成个性化的翻唱作品,无论你是音乐爱好者还是专业创作者,掌握录制AI翻唱模型的方法,可以大大丰富你的创作手段,下面,我将一步步介绍如何完成这个过程,从准备工具到最终输出,确保内容实用且易于上手。
我们需要明确AI翻唱模型的基本概念,这类模型通常基于深度学习算法,例如卷积神经网络或循环神经网络,它们通过分析大量音频数据来学习特定歌手的声音特征,录制AI翻唱的核心在于训练或使用预训练模型,生成符合你需求的翻唱音频,整个过程可以分为数据准备、模型选择、训练与生成、后期处理等环节。
在开始之前,选择合适的工具至关重要,市面上有多种AI翻唱软件和平台,例如开源框架TensorFlow或PyTorch下的语音合成模型,以及一些在线服务如基于WaveNet的应用,如果你是新手,建议从用户友好的界面入手,比如那些提供图形化操作的平台,这样可以避免复杂的编程步骤,选择工具时,考虑其兼容性,例如支持常见的音频格式如WAV或MP3,并确保它能在你的设备上稳定运行。
数据准备是录制AI翻唱的基础步骤,如果你计划训练自定义模型,需要收集目标歌手的音频样本,这些样本应当质量高、无背景噪音,并且覆盖多种音域和情感表达,推荐使用专业录音设备或高质量麦克风来采集原始音频,然后通过软件如Audacity进行预处理,预处理包括去除杂音、标准化音量以及分割成短片段,以便模型更好地学习特征,如果使用预训练模型,这一步可以简化,但确保输入音频清晰,能提高生成效果。
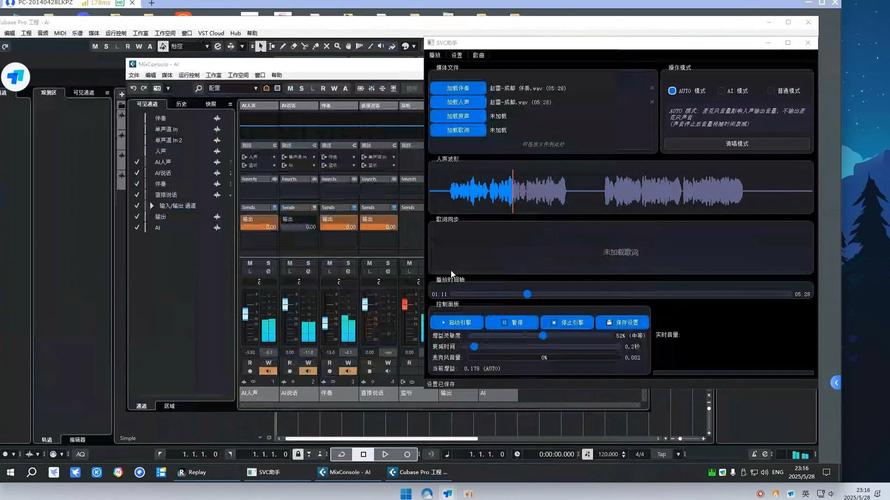
接下来是模型训练环节,如果你选择训练自己的模型,需要将准备好的数据导入工具中,设置参数如学习率、批量大小和训练轮数,训练过程可能耗时较长,从几小时到数天不等,取决于数据量和硬件性能,使用GPU加速可以显著提升效率,在训练中,定期检查生成样本的质量,避免过拟合或欠拟合问题,一旦模型收敛,保存权重文件以备后用。
生成翻唱音频时,输入你想要翻唱的歌曲文件,这可以是原唱的干声轨道或MIDI序列,确保输入干净无干扰,运行模型后,它会输出模拟的翻唱版本,初次生成可能不够完美,常见问题包括音高不准或节奏偏差,这时需要多次调整输入参数或重新训练部分数据。
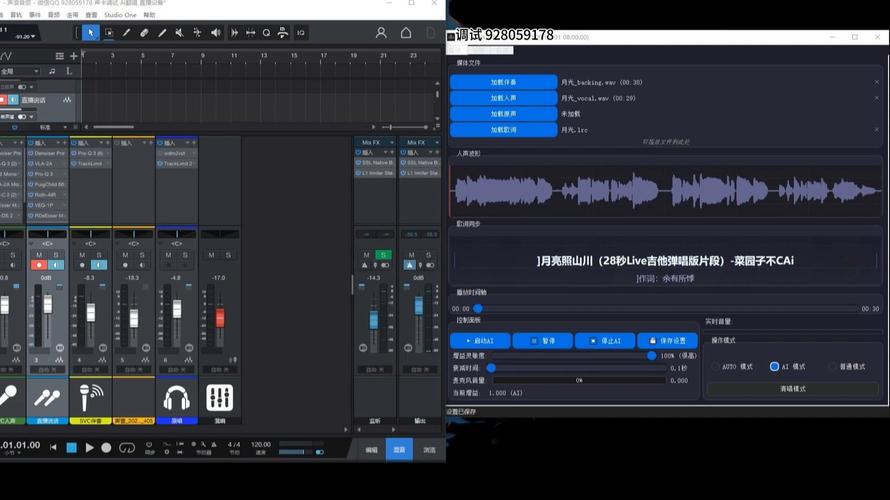
后期处理是提升成品质量的关键,使用数字音频工作站软件,例如FL Studio或Adobe Audition,对生成的音频进行编辑,重点调整均衡器以平衡频段,应用压缩器控制动态范围,并添加混响或延迟效果增强空间感,检查音频与伴奏的同步性,必要时手动修正时间轴,导出时,选择高比特率格式如320kbps的MP3或无损WAV,以保证播放兼容性。
在整个过程中,注意常见陷阱,数据不足可能导致模型泛化能力差;过度依赖预训练模型可能限制自定义空间,建议从简单歌曲开始练习,逐步积累经验,保持耐心,AI翻唱技术仍在发展中,生成结果可能因模型而异。
从个人角度看,AI翻唱模型为音乐创作开辟了新路径,它让普通人也能体验专业制作,并促进创意表达,这项技术也带来挑战,如版权问题和声音伦理考量,作为使用者,我们应当尊重原创作品,合理应用AI工具,避免侵犯他人权益,展望未来,随着算法优化,AI翻唱或许能更精准地捕捉情感细节,但核心价值仍在于人类的艺术直觉,通过不断学习和实践,每个人都能在这个领域找到属于自己的声音。

 13888888888
13888888888

 点击咨询
点击咨询 