在当今技术快速发展的时代,越来越多的开发者和企业开始关注在本地训练AI编程模型的可能性,相比于依赖云端服务,本地训练提供了更高的数据隐私性、更灵活的控制以及更低的长期成本,成功训练一个本地AI模型并不是一件简单的事,它涉及多个环节的细致设计与优化。
要开始训练一个本地的AI模型,首先需要明确目标和需求,不同的任务需要不同类型的模型,如果是处理图像识别,卷积神经网络(CNN)可能是合适的选择;而自然语言处理(NLP)任务则可能更适合使用Transformer结构,确定任务类型后,就可以进入下一个阶段:数据准备。
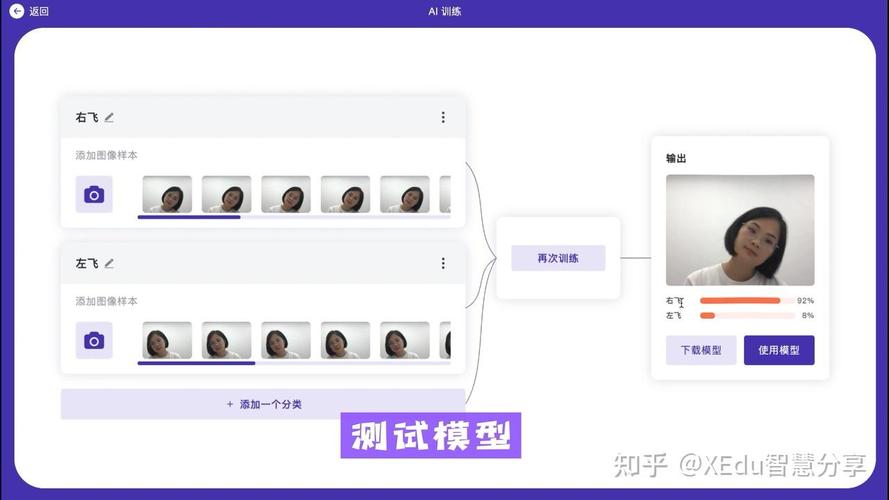
数据是AI模型的基石,无论是监督学习、无监督学习还是强化学习,高质量的数据集都是不可或缺的,在本地环境中,数据的收集、清洗和标注需要投入大量精力,确保数据具有代表性、无偏见且覆盖足够多的场景,是训练出稳健模型的前提,本地训练还意味着数据不需要离开内部服务器,这对于涉及敏感信息的行业(如医疗、金融或法律)尤为重要。
完成数据准备工作后,接下来是搭建训练环境,本地训练通常依赖于一台或多台配备高性能GPU的机器,GPU因其强大的并行计算能力,能够显著加速模型训练过程,除了硬件,软件环境也同样重要,常见的深度学习框架如TensorFlow、PyTorch或JAX都提供了丰富的工具和接口来支持模型开发和训练,正确配置CUDA驱动、Python环境以及相关依赖库是确保训练流程顺畅的关键。
模型设计是训练过程中的核心环节,根据任务复杂度,可以选择使用现有的预训练模型进行微调,也可以从头开始构建一个新模型,微调预训练模型(例如BERT或ResNet)通常能够节省大量时间和计算资源,尤其在数据量有限的情况下表现尤为突出,而如果任务非常特殊或创新,则可能需要自定义模型结构,深入理解各类神经网络层的工作原理及其适用场景至关重要。
一切就绪后,便可以启动训练过程,在训练中,超参数的选择对模型性能影响显著,学习率、批大小、优化器类型、正则化方法等都需要通过实验不断调整,使用验证集对训练过程进行监控,并借助早停(early stopping)策略防止过拟合,是提高模型泛化能力的有效手段,训练过程中可能会遇到梯度消失或爆炸、训练不稳定等问题,这时需要灵活调整模型结构或优化策略。
训练完成后,模型的评估与验证不可或缺,仅仅依靠训练集上的表现是不够的,必须在独立的测试集上全面评估模型的准确率、召回率、F1分数等指标,对于分类任务,混淆矩阵可以帮助分析模型在各类别上的表现;对于回归任务,则需关注均方误差或平均绝对误差等指标,只有通过严格评估的模型,才具备实际应用的价值。
训练好的模型需要部署到实际应用中,本地部署可以采取多种形式,例如集成到现有软件系统、封装为API服务或嵌入边缘设备,值得注意的是,模型部署并不是终点,而是一个持续迭代的起点,在实际使用中,模型的性能可能会因数据分布变化而下降,因此定期使用新数据对模型进行再训练是维持其效果的必要措施。
在整个本地AI模型训练的过程中,挑战与机遇并存,数据的质量、算力的限制以及模型设计的复杂性都是需要克服的困难,掌握本地训练的能力不仅能够增强技术自主性,还能在数据安全和定制化需求方面带来显著优势,对于技术团队而言,持续学习、积极实践、不断积累经验,是走向成功的关键,每一步的扎实进展,都将为未来的AI应用奠定更加坚实的基础。

 13888888888
13888888888

 点击咨询
点击咨询 