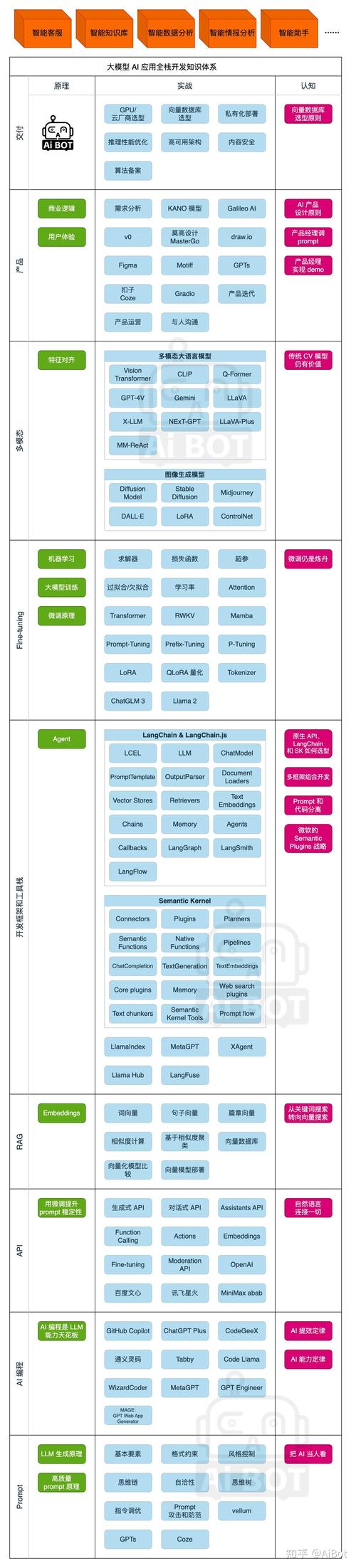
理解AI模型的基本构成
在开始下载自己的AI模型之前,我们需要先理解AI模型的基本构成,一个AI模型通常由几个核心部分组成:架构文件、权重参数以及相关的配置文件,架构文件定义了模型的结构,比如神经网络的层数、节点数量等;权重参数则是模型通过训练学到的知识,决定了模型的具体表现;配置文件则包含了一些超参数和运行环境的设置。
这些文件通常以特定的格式保存,常见的格式有HDF5、Pickle、ONNX、PB(Protocol Buffers)等,不同的框架和平台可能支持不同的格式,因此在下载前需要明确自己的使用场景和需求。

选择合适的模型来源
下载自己的AI模型,首先需要明确模型的来源,通常情况下,AI模型来源于以下几个渠道:自己训练的模型、从开源平台获取的预训练模型,或者从商业平台购买的模型,如果是自己训练的模型,那么下载过程相对直接,因为你可以完全控制模型的生成和存储环境。
对于开源预训练模型,常见的来源包括Hugging Face、TensorFlow Hub、PyTorch Hub等平台,这些平台提供了大量的预训练模型,覆盖了自然语言处理、计算机视觉、语音识别等多个领域,在选择模型时,需要注意模型的许可证、适用场景以及性能指标,确保模型符合你的需求。
下载自己训练的模型
如果你是自己训练模型,下载过程通常涉及从训练环境中导出模型文件,以TensorFlow为例,你可以使用tf.saved_model.save函数将模型保存为SavedModel格式,这是一种常见的模型保存方式,适用于生产环境,保存后的模型包含一个包含架构和权重的文件夹,你可以直接下载到本地。
对于PyTorch用户,常见的做法是使用torch.save函数将模型的状态字典(state_dict)保存为.pth文件,状态字典包含了模型的所有权重参数,但不包含模型架构,在下载后,你需要同时保存模型的定义代码,以便在加载时重建模型。
除了框架自带的保存方式,还可以将模型转换为通用格式,如ONNX,ONNX是一种开放的模型格式,支持跨框架使用,通过转换为ONNX格式,你可以更方便地在不同平台和设备上部署模型。
从开源平台下载预训练模型
如果你是从开源平台下载预训练模型,过程通常比较简单,以Hugging Face为例,你可以通过其提供的API或命令行工具直接下载模型,使用transformers库中的from_pretrained方法,可以自动下载并加载模型,下载的模型会缓存到本地目录,你可以直接访问这些文件进行后续操作。
TensorFlow Hub和PyTorch Hub也提供了类似的功能,你可以通过几行代码直接下载并使用预训练模型,需要注意的是,下载的模型文件可能包含多个部分,如权重、词汇表、配置文件等,确保下载完整的模型文件以便正确使用。
模型下载后的处理与管理
下载模型后,还需要进行一些处理和管理工作,验证模型的完整性和正确性,可以通过加载模型并运行一些测试数据来确认模型是否正常工作,考虑模型的存储和版本管理,建议使用版本控制工具(如Git)或模型管理平台(如MLflow)来跟踪模型的变更和历史。
模型的安全性和隐私性也需要重视,如果模型包含敏感数据或用于敏感任务,确保下载和存储过程符合相关法律法规和隐私政策,加密模型文件、限制访问权限是常见的保护措施。
个人观点
AI模型的下载看似简单,但实际上涉及多个环节,从选择来源到后续管理,都需要仔细考虑,作为一名网站站长,我建议大家在下载和使用模型时,始终以实际需求为导向,注重模型的适用性和可靠性,保持对新技术和工具的关注,能够帮助我们更高效地完成这项工作,毕竟,AI技术的快速发展为我们提供了更多可能性,但同时也要求我们不断学习和适应。

 13888888888
13888888888

 点击咨询
点击咨询 