在人工智能技术日益普及的今天,越来越多的开发者和企业开始关注如何在本地环境中部署和训练自己的AI模型,这种方式不仅能够更好地控制数据隐私,还能根据具体需求灵活调整模型结构,减少对云端服务的依赖,本文将系统介绍本地部署AI模型的基本流程与关键要点,帮助读者初步掌握相关方法。
要实现本地训练,首先需明确目标与资源情况,不同的任务需要不同类型的模型,而硬件条件直接限制了训练的可行性,基于Transformer的大规模语言模型通常需要大量的显存和计算资源,而轻量级的图像分类模型则可以在普通消费级显卡上运行,在开始之前,应合理评估可用硬件(如GPU显存、内存和存储空间),并据此选择适当的模型架构。
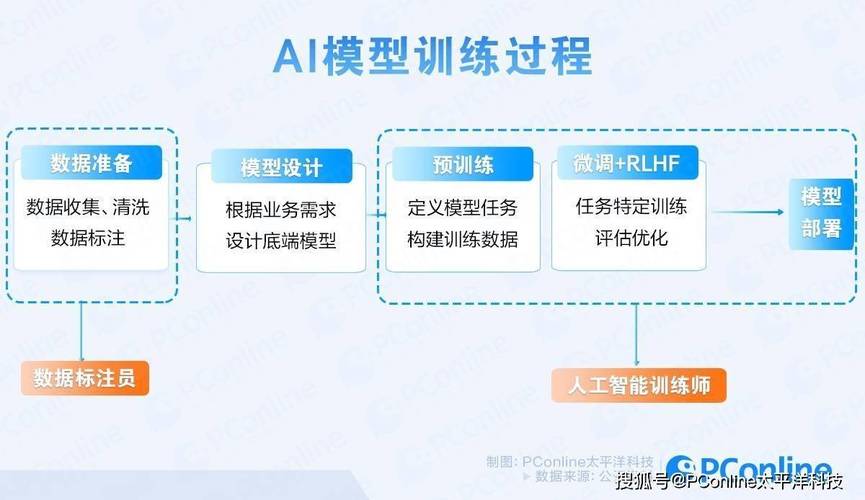
接下来是环境配置,本地训练通常依赖于深度学习框架,例如TensorFlow、PyTorch或JAX,这些工具提供了丰富的API和预构建模块,大大简化了模型搭建的过程,建议通过Anaconda或Docker等工具构建独立的Python环境,以避免依赖冲突,安装对应版本的CUDA和cuDNN驱动对于GPU加速至关重要。
数据是模型训练的基础,高质量的数据集直接影响最终模型的性能,在本地环境下,数据预处理环节需要格外注意——包括数据清洗、标注校验、格式统一以及合理划分训练集、验证集和测试集,对于图像、文本或音频等不同类型的数据,还需进行特定的增强操作(如旋转、裁剪、添加噪声等),以提升模型泛化能力。

模型选择与构建环节应结合具体任务,如果是图像识别,可考虑ResNet或EfficientNet;若是自然语言处理任务,BERT或GPT系列模型可能更合适,初学者可以从预训练模型出发,通过微调(fine-tuning)的方式适应本地数据,这不仅节省时间,也能在一定程度上提升效果。
训练过程是核心环节,需要合理设置超参数,包括学习率、批次大小(batch size)、优化器类型和训练轮数(epoch),学习率过高可能导致训练不稳定,而过低则会延长收敛时间,建议使用学习率调度策略,如余弦退火或预热步骤,早停(early stopping)机制和模型检查点(checkpoint)保存能有效防止过拟合和意外中断导致的数据丢失。

在训练中,监控与评估同样重要,利用TensorBoard或Weights & Biases等可视化工具,可以实时跟踪损失函数、准确率等指标的变化趋势,验证集上的表现应作为调整超参数和判断训练状态的主要依据。
训练完成后,需对模型进行系统评估,除了常规的准确率、精确率和召回率,还可通过混淆矩阵、ROC曲线等方式深入分析模型在不同类别上的表现,只有经过充分测试的模型,才能投入实际应用。
模型部署是最后的关键一步,本地部署可选择多种形式,如封装为API服务、集成到现有应用程序中,或构建图形化界面供终端用户使用,常用工具包括FastAPI、Flask或TensorFlow Serving等,值得注意的是,部署时还需考虑模型版本管理、推理效率优化和资源占用控制等问题。
关于本地训练的优势,很多人看重的是数据隐私和安全性的保障,尤其对于医疗、金融等敏感行业,本地化处理能有效避免数据外泄风险,长期来看,本地部署也有助于降低使用成本,尤其当模型需频繁调用时。
本地训练也面临一些挑战,硬件投入成本较高、技术门槛相对较高,以及扩展性不如云端灵活,是否选择本地方案,应基于实际需求、资源条件和团队能力进行综合权衡。
从技术发展趋势来看,随着模型压缩和蒸馏技术的发展,越来越多的先进模型正变得轻量化,更适合在本地设备运行,开源社区的活跃也为开发者提供了丰富的工具和资源,使得本地训练变得更加可行。
对于初学者而言,建议从一些小规模项目开始,逐步积累经验,参与开源项目、阅读优秀代码和加入技术社区交流,都是提升能力的有效途径,只有在实践中不断尝试和优化,才能真正掌握本地训练AI模型的核心方法。
人工智能的本质是为人类服务,而本地部署恰恰提供了一种更自主、可控的技术实现路径,随着相关工具链的不断完善,我们有理由相信,未来会有更多创新应用诞生于本地环境中。

 13888888888
13888888888

 点击咨询
点击咨询 