训练人工智能识别模型是一个系统性的过程,涉及多个关键环节,无论是图像识别、语音处理还是文本分析,核心原理都基于数据驱动的方法,下面将详细介绍训练的基本步骤和注意事项,帮助您理解这一过程。
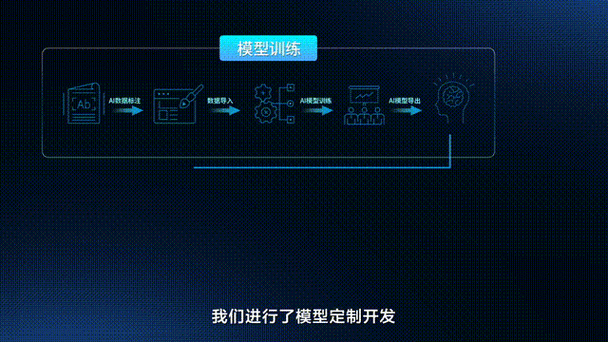
数据收集是训练模型的基石,没有高质量的数据,模型就无法学习有效的特征,数据来源可以包括公开数据集、自行采集或第三方提供,在图像识别任务中,可能需要数千张标注好的图片,每张图片都标有对应的类别,如“猫”或“狗”,数据标注需要精确一致,否则模型会学习到错误模式,数据量越大,模型泛化能力通常越强,但也要注意平衡,避免收集无关信息,数据质量检查包括去除重复项、纠正错误标签和处理缺失值,这一步能显著提升后续训练效率。
数据预处理是下一个关键阶段,原始数据往往包含噪声或不一致格式,需要通过清洗和转换来优化,常见操作包括归一化(将数据缩放到统一范围)、数据增强(通过旋转、裁剪或添加噪声来扩展数据集)和特征提取(例如从图像中提取边缘或颜色直方图),预处理不仅能提高模型性能,还能减少训练时间,在自然语言处理中,文本数据可能需要分词、去除停用词或转换为向量表示,这一步骤需要根据具体任务定制,确保数据适合模型输入。
选择模型架构是训练过程中的核心决策,不同任务适用不同的模型类型,对于图像识别,卷积神经网络(CNN)是常见选择,因为它能有效捕捉空间特征;对于序列数据如语音或文本,循环神经网络(RNN)或Transformer模型可能更合适,初学者可以从预训练模型开始,例如使用ResNet或BERT作为基础,通过微调适应新任务,模型选择时需考虑复杂度:简单模型训练快但可能欠拟合,复杂模型则容易过拟合,平衡模型深度和参数数量是关键,通常需要实验来确定最优架构。
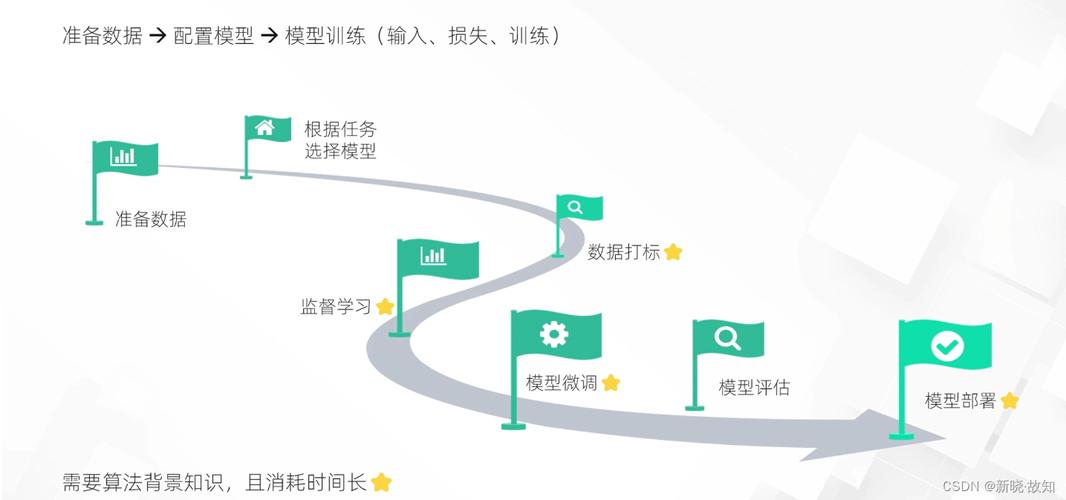
训练阶段涉及将数据输入模型,并通过优化算法调整参数,这一过程使用损失函数来衡量预测与真实值的差距,然后通过反向传播更新权重,超参数设置如学习率、批次大小和迭代次数对结果影响很大,学习率过高可能导致训练不稳定,过低则收敛慢;批次大小会影响内存使用和梯度稳定性,实践中,常用随机梯度下降或其变体(如Adam优化器)来加速收敛,训练过程中,监控损失和准确率曲线很重要,如果出现震荡或下降缓慢,可能需要调整超参数或检查数据问题。
模型评估是验证性能的必要步骤,使用独立的测试集来评估模型,避免使用训练数据,以防止过拟合,常用指标包括准确率、精确率、召回率和F1分数,具体选择取决于任务需求,在医疗图像识别中,高召回率可能比准确率更重要,以减少漏诊风险,交叉验证方法可以进一步确保结果稳健,如果模型在测试集上表现不佳,可能需返回数据或模型阶段进行改进。
优化和迭代是训练模型的持续环节,模型初次训练后,往往需要通过正则化(如Dropout或L2正则化)来减少过拟合,或使用早停法防止训练过度,集成学习(结合多个模型)也能提升性能,关注计算资源:训练大型模型可能需要GPU加速,而边缘设备上部署则需模型压缩技术,迭代过程中,记录每次实验的配置和结果,便于分析和复现。
从个人经验看,训练AI识别模型不仅是技术活,更是一门艺术,它要求我们保持耐心,不断实验和学习,现实世界中,数据往往不完美,模型需要适应变化的环境,我认为,未来AI训练会更注重自动化工具和可解释性,让更多人能参与创新,关键是培养数据驱动的思维,同时警惕伦理问题,如偏见和隐私保护,通过持续实践,任何人都能逐步掌握这项技能,推动技术进步。

 13888888888
13888888888

 点击咨询
点击咨询 