在自然语言处理(NLP)领域,Word向量是一种将单词转换为数值形式的方法,这种方法使得计算机能够理解和处理文本数据,Word向量有多种表示方法,如词袋模型、TF-IDF和词嵌入等,本文将详细介绍如何查看Word向量,以及如何使用这些信息进行文本分析和处理。
什么是Word向量?
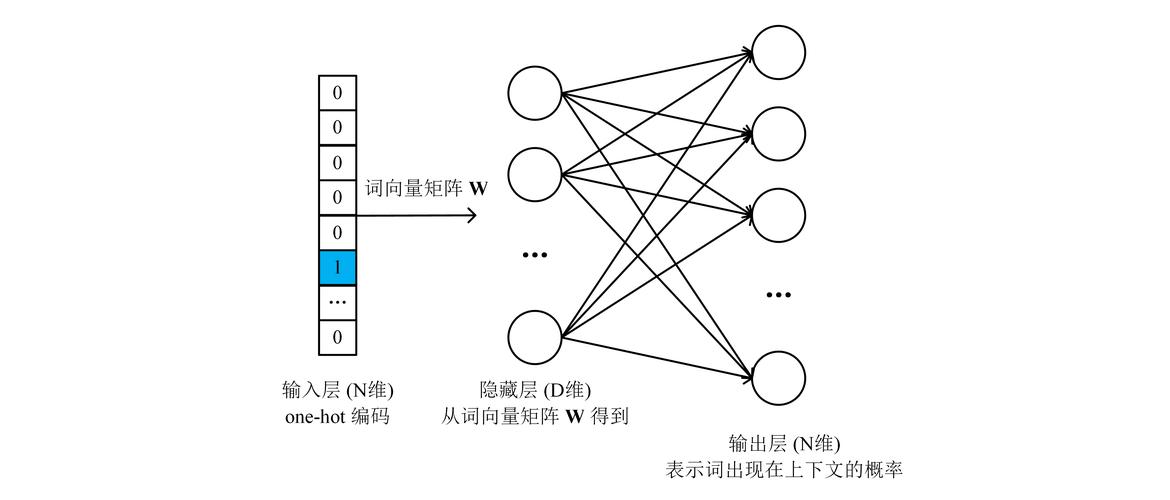
Word向量,也叫词向量,是将单词转换为数值形式的一种方法,在传统的文本处理方法中,我们通常使用词袋模型或者TF-IDF来表示文本,这些方法存在一些问题,如无法捕捉到单词之间的语义关系,为了解决这个问题,研究人员提出了词嵌入的概念,词嵌入是一种将单词映射到一个高维空间中的技术,使得相似的单词在空间中的距离较近。
如何查看Word向量?
要查看Word向量,我们需要使用一些工具和技术,以下是一些常用的方法和库:
1、Word2Vec:这是一个非常流行的词嵌入模型,由Google的Tomas Mikolov等人提出,Word2Vec可以将单词映射到一个高维空间中,使得相似的单词在空间中的距离较近,我们可以使用Gensim库来实现Word2Vec。
2、GloVe:这是另一个流行的词嵌入模型,由斯坦福大学的Jeffrey Pennington等人提出,GloVe结合了局部上下文和全局统计信息,可以更好地捕获单词之间的语义关系,我们可以使用Gensim库来实现GloVe。
3、FastText:这是Facebook提出的一个词嵌入模型,它可以处理未知单词和子词级别的信息,FastText同样可以使用Gensim库来实现。
4、BERT:这是近年来非常流行的一个预训练语言模型,由Google的Jacob Devlin等人提出,BERT通过自注意力机制来捕获单词之间的语义关系,可以在多种NLP任务上取得很好的效果,我们可以使用Hugging Face的Transformers库来实现BERT。
5、表格展示:为了更好地理解Word向量,我们可以将其以表格的形式展示出来,我们可以创建一个包含单词、向量维度和向量值的表格,如下所示:

| 单词 | 向量维度 | 向量值 |
| 苹果 | 300 | [0.5, -0.2, 0.1, ...] |
| 香蕉 | 300 | [0.6, -0.1, 0.2, ...] |
| 橙子 | 300 | [0.7, -0.3, 0.3, ...] |
通过这种方式,我们可以直观地看到不同单词在高维空间中的表示。
如何使用Word向量进行文本分析?
Word向量在文本分析中有很多应用,如情感分析、主题建模、命名实体识别等,以下是一个简单的例子,演示如何使用Word向量进行文本分类:
1、准备数据集:我们需要准备一个包含文本和标签的数据集,我们可以使用IMDb电影评论数据集,其中包含了5万条电影评论和对应的情感标签(正面或负面)。
2、训练词嵌入模型:我们可以使用Word2Vec或其他词嵌入模型来训练一个词嵌入模型,在这个例子中,我们将使用Word2Vec,我们可以使用Gensim库来实现Word2Vec的训练过程。
3、提取特征:一旦我们训练好了词嵌入模型,我们就可以使用它来将文本数据转换为Word向量,对于每个单词,我们都可以找到其对应的向量表示,我们可以将这些向量拼接起来,形成一个固定长度的特征向量。
4、训练分类器:我们可以使用这些特征向量来训练一个分类器,在这个例子中,我们将使用逻辑回归作为分类器,我们可以使用Scikit-learn库来实现逻辑回归的训练过程。
5、评估模型性能:在训练完成后,我们可以使用测试集来评估模型的性能,我们可以计算准确率、召回率和F1分数等指标来衡量模型的效果,如果模型表现不佳,我们可以尝试调整参数或更换其他算法来提高性能。
Word向量是一种强大的工具,可以帮助我们在文本分析中捕捉到单词之间的语义关系,通过使用各种词嵌入模型和库,我们可以方便地生成和查看Word向量,并将其应用于各种NLP任务中。
到此,以上就是小编对于word向量怎么看的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位朋友在评论区讨论,给我留言。
内容摘自:https://news.huochengrm.cn/zcjh/11029.html 13888888888
13888888888

 点击咨询
点击咨询 