在处理文本数据时,我们可能会遇到乱码的情况,这通常是由于编码不匹配或数据传输错误导致的,如果你手头有一份包含乱码的文档,并希望将其转换为可读的Word格式,以下是一些详细的步骤和技巧,帮助你实现这一目标。
识别乱码的类型
你需要确定乱码的类型,常见的乱码类型包括:
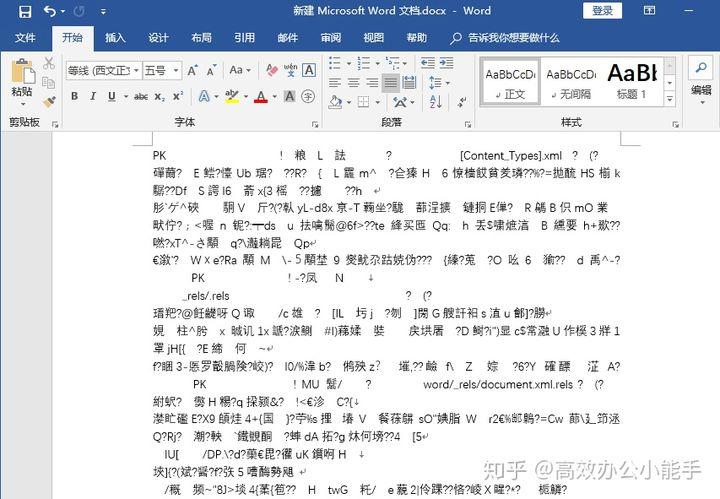
ASCII乱码:通常表现为一系列问号(?)或其他不可识别的字符。
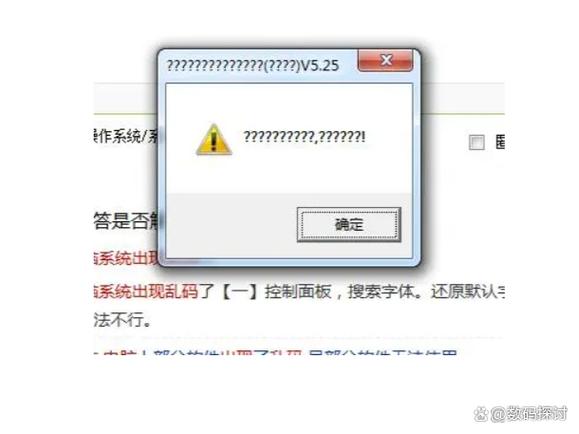
Unicode乱码:可能显示为方块(□)或其他非英文字符。
编码不匹配:将UTF-8编码的文本以GBK编码打开,会导致中文字符显示为乱码。
转换乱码为可读文本
1. 使用文本编辑器
大多数现代文本编辑器(如Notepad++、Sublime Text等)都支持多种编码格式,你可以尝试以下步骤:
打开乱码文件。
尝试不同的编码格式(如UTF-8、GBK、Big5等),直到文本变得可读。
保存为正确的编码格式。
2. 在线工具
如果文本编辑器无法解决问题,你可以尝试使用在线乱码转换工具,这些工具通常允许你上传文件或输入文本,并选择源编码和目标编码进行转换。
3. 编程方法
对于更复杂的情况,你可以使用编程语言(如Python)来处理乱码,以下是一个简单的Python示例,用于将乱码文本转换为可读格式:
假设原文本是utf-8编码,但被误读为gbk编码
original_text = b'\xc4\xe3\xba\xc3' # 乱码字节串
corrected_text = original_text.decode('gbk').encode('utf-8') # 解码再重新编码
print(corrected_text.decode('utf-8')) # 输出可读文本将文本导入Word
一旦你得到了可读的文本,就可以轻松地将其导入Word了:
打开Microsoft Word。
选择“文件”>“打开”,然后选择你的文本文件。
Word会自动将文本转换为可编辑的格式。
如果需要,你可以进一步调整字体、段落格式等。
预防乱码问题
为了避免未来再次遇到乱码问题,你可以采取以下措施:
确保所有涉及的系统和软件都使用相同的编码标准(推荐使用UTF-8)。
在传输文本文件时,明确指定编码格式。
定期备份重要数据,以防数据丢失或损坏。
FAQs
Q1: 如果我不知道乱码的具体类型,应该怎么办?
A1: 你可以尝试使用不同的编码格式来打开文件,直到找到一种使文本变得可读的编码,大多数文本编辑器都提供了这种功能,如果仍然无法解决,考虑寻求专业帮助或使用在线乱码转换工具。
Q2: 将乱码转换为可读文本后,如何确保Word中的格式正确?
A2: 在将文本导入Word后,你可能需要手动调整一些格式设置,如字体、段落间距等,如果你的原始文本包含特殊的格式标记(如HTML标记),Word可能无法完全保留这些格式,在这种情况下,你可能需要手动应用格式或使用其他工具来辅助格式化。
以上就是关于“怎么把乱码变成word”的问题,朋友们可以点击主页了解更多内容,希望可以够帮助大家!
内容摘自:https://news.huochengrm.cn/zcjh/23304.html 13888888888
13888888888

 点击咨询
点击咨询 