人工智能技术的快速发展使得训练大模型成为行业焦点,作为网站站长,我观察到许多从业者对这一过程存在误解,本文将系统梳理训练AI大模型的完整流程,并分享个人在实践中的经验认知。
数据是模型的基础
训练优秀的大模型始于高质量数据,建议构建覆盖多领域的语料库,包含学术论文、新闻资讯、专业书籍等不同文本类型,数据清洗时需特别注意:去除重复内容、修正错别字、过滤敏感信息,某知名实验室曾公开其数据处理标准——每百万字符中允许的噪声数据不超过3%,实际操作中可采用词频统计工具辅助筛查,同时建立人工复核机制。
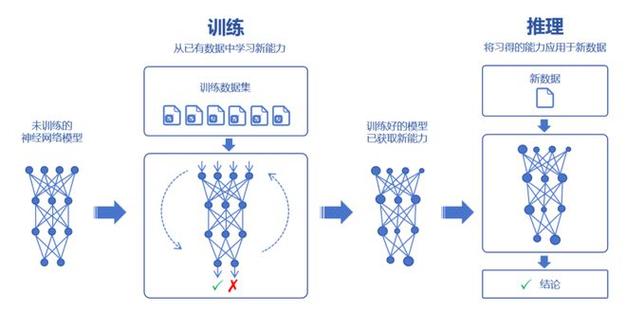
架构选择决定模型上限
当前主流模型架构主要基于Transformer框架,研究者需要根据应用场景调整网络深度、注意力头数量等参数,例如对话类模型通常需要更深的解码器层,而文本生成模型可能侧重多头注意力的组合方式,建议初期参考已公开的成熟架构,如GPT系列或BERT的变体,待数据量积累到特定规模后再进行创新性调整。
计算资源优化策略
分布式训练已成为大模型训练的标配,建议采用混合并行策略:数据并行处理批量样本,模型并行拆分网络层,使用梯度累积技术可有效降低显存占用,当使用8张A100显卡时,合理设置梯度累积步数能使有效批处理量提升4倍,监控系统需实时跟踪GPU利用率,理想状态应保持在85%以上。
训练过程中的关键技术
学习率调度直接影响模型收敛速度,余弦退火策略配合热启动已被证明在多数场景有效,损失函数设计需考虑任务特性,分类任务建议尝试标签平滑技术,生成任务可引入多样性惩罚项,某头部企业技术白皮书显示,恰当的正则化手段能使模型泛化能力提升23%。
评估体系的建立
传统准确率指标已无法全面评估大模型性能,建议构建三级评估体系:基础指标(困惑度、BLEU值)、任务指标(问答准确率、生成连贯性)、人类评估(专业评审团打分),特别注意模型输出的安全性评估,建立包含2000+风险案例的测试集,覆盖伦理、法律等多维度问题。
持续迭代的重要性
模型上线后需建立反馈闭环,部署在线学习模块时,建议采用双模型轮换机制——当前服务模型与影子模型并行运行,通过A/B测试收集用户真实交互数据,某电商平台实践表明,持续迭代的模型在六个月内点击率提升17%,用户留存率增加9%。
伦理与合规的边界
训练过程必须遵守数据隐私法规,采用差分隐私技术处理用户数据,模型输出层应加入内容过滤模块,建议组合关键词过滤、语义分析和人工审核三重机制,开发团队需要定期进行伦理审查,建立可追溯的决策日志系统。
训练AI大模型是系统工程,需要技术能力与工程经验的深度融合,从业者既要保持对前沿技术的敏感度,又要注重基础能力的持续打磨,在这个过程中,耐心比天赋更重要,细节决定最终成败,当看到模型开始产出有价值的成果时,那种技术突破带来的满足感,正是驱动我们不断探索的动力源泉。

 13888888888
13888888888

 点击咨询
点击咨询 