上海AI大模型训练:数据、算力与创新的深度交响
在上海这片科技创新的热土上,人工智能大模型的训练并非凭空诞生,而是依托于坚实的技术底座与前瞻性的战略布局,驱动这场智能革命的引擎,主要由三个核心支柱构成:
算力:城市级基础设施的强力支撑 上海已构建起强大的算力网络,临港新片区国际数据港、长三角生态绿色一体化发展示范区数据中心集群等重大项目,正加速提供澎湃的算力资源,商汤科技、天数智芯等本地企业研发的AI芯片,以及高校与超算中心的联合算力平台,为千亿级参数模型的训练提供了坚实的物质基础,分布式训练框架的成熟运用,使庞大模型得以在多GPU集群上高效并行运算。
数据:高质量语料的战略汇聚 大模型的智慧源于海量优质数据,上海作为国际金融、贸易、航运中心,天然汇聚了多维度、高价值的行业数据资源,在严格遵守数据安全法规的前提下,以上海公共数据开放平台为代表,积极探索政务、金融、医疗等领域的合规数据开放与融合应用模式,企业、高校及研究机构也积极构建涵盖文本、代码、多模态的专业数据集,为模型注入丰富的“知识养料”。
人才:顶尖智力的持续输出 上海交通大学、复旦大学、同济大学等顶尖学府设立了专门的人工智能学院与研究机构,源源不断地培养AI算法、系统工程等领域的顶尖人才,微软亚洲研究院(上海)、上海人工智能实验室、期智研究院等高端研究平台,以及众多科技巨头的上海研发中心,汇聚了全球顶尖的科学家与工程师,他们是模型架构设计、算法创新的核心驱动力。

揭秘上海大模型训练的严谨流程
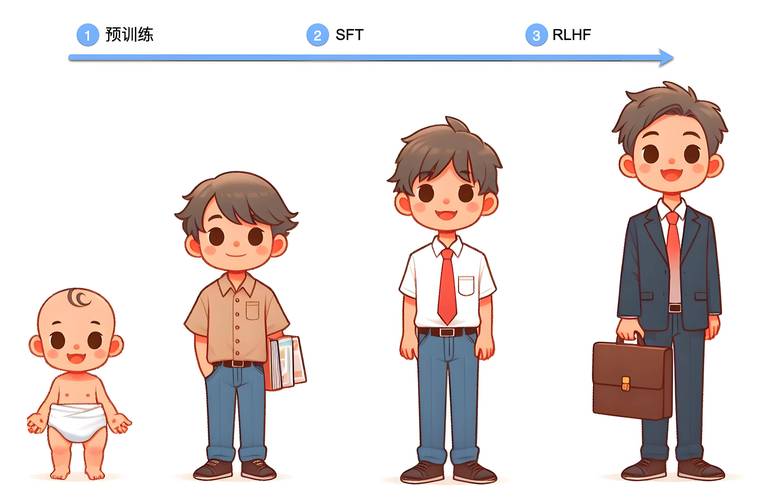
第一阶段:数据工程 - 构建高质量知识基石 训练的第一步始于海量数据的严格筛选与清洗,工程师们会去除重复、低质、有害信息,确保数据的纯净度,针对中文语境与上海本地特色(如金融术语、政策文件、方言表达),还需进行深度预处理与标注,上海人工智能实验室在训练“书生”模型时,特别强化了金融、法律等专业中文语料库的建设,数据多样性至关重要,需涵盖通用知识、专业技术、文化背景等多方面。
第二阶段:预训练 - 赋予模型基础认知能力 在拥有强大算力的GPU集群上,模型开始进行大规模自监督学习,它通过掩码语言建模(MLM)等方式,从海量文本中自动学习语言规律、世界知识与上下文逻辑,这一阶段消耗的算力与时间最为巨大,模型逐步建立起对世界的初步“理解”,优化技术如混合精度训练(FP16/FP32结合)、ZeRO优化器等被广泛应用,以提升效率、节省显存。
第三阶段:精调与对齐 - 塑造专业能力与价值观 预训练后的模型如同“通才”,需经指令精调(Instruction Tuning) 与基于人类反馈的强化学习(RLHF) 才能成为特定领域的“专家”或安全可靠的助手,上海的研究机构与企业尤其注重:
- 行业专业化精调: 如使用金融对话、医疗文献、工业知识图谱等数据,训练出懂金融、懂医疗、懂制造的垂直领域模型。
- 价值观对齐: 严格遵循中国法律法规与伦理规范,通过精心设计的数据和RLHF流程,确保模型输出安全、可靠、符合社会主义核心价值观,上海近期发布的《上海市促进人工智能产业发展条例》为这一过程提供了明确指引。
第四阶段:评估与迭代 - 追求卓越性能 训练完成的模型需经受严格的多维度评估:
- 通用能力测试: 在语言理解、推理、创作等标准基准(如CEval、MMLU中文版)上衡量表现。
- 行业场景验证: 在金融风控、智能客服、药物研发等真实应用环境中测试实用性与准确性。
- 安全伦理审查: 通过对抗性测试、偏见检测等手段,评估模型的安全性、公平性与可控性。 评估结果驱动模型的持续迭代优化,形成闭环。
上海特色:场景驱动与生态协同
上海大模型训练的独特优势在于紧密连接丰富的落地场景与强大的产学研协同生态,从张江科学城的生物医药AI研发,到陆家嘴的智能金融应用,再到洋山港的智慧物流调度,真实世界的复杂需求为模型训练提供了明确目标与验证舞台,政府积极搭建平台(如世界人工智能大会),促进企业、高校、研究机构间的深度合作与技术共享,加速了从理论突破到产业应用的转化效率。
上海AI大模型的崛起,绝非单纯的技术堆砌,而是顶层设计、资源聚合、场景深耕与持续创新的系统成果,这座城市正以开放包容的姿态、扎实的工程能力和对前沿的敏锐把握,在中国乃至全球的人工智能版图上刻下鲜明的“上海印记”,其发展路径深刻印证了“协同创新”是驱动重大技术突破的核心动能。

 13888888888
13888888888

 点击咨询
点击咨询 