在魔塔社区中,训练AI模型是推动创新和解决实际问题的核心环节,作为社区成员或初学者,了解这一过程能帮助您高效地构建智能系统,AI模型训练本质上是让算法从数据中学习模式,最终实现预测或决策功能,这不仅需要技术知识,还依赖社区的协作资源,下面,我将详细阐述魔塔社区中AI模型训练的关键步骤,分享实用建议,助您上手。
数据准备:构建坚实的基础
任何AI模型的成功始于高质量数据,在魔塔社区,成员们常强调数据是模型的“燃料”,收集相关数据集至关重要,如果您开发图像识别模型,需从开放平台或社区共享库中获取标注图像,魔塔社区提供工具如数据清洗脚本,帮助去除噪声、处理缺失值,确保数据多样性,避免偏差——如果数据集只包含特定场景,模型可能在现实应用中失效,数据预处理包括标准化和增强,如旋转图像或添加噪声,提升模型泛化能力,社区经验表明,投入时间在数据阶段能节省后期训练成本,建议使用开源工具如TensorFlow或PyTorch,结合社区论坛讨论最佳实践。
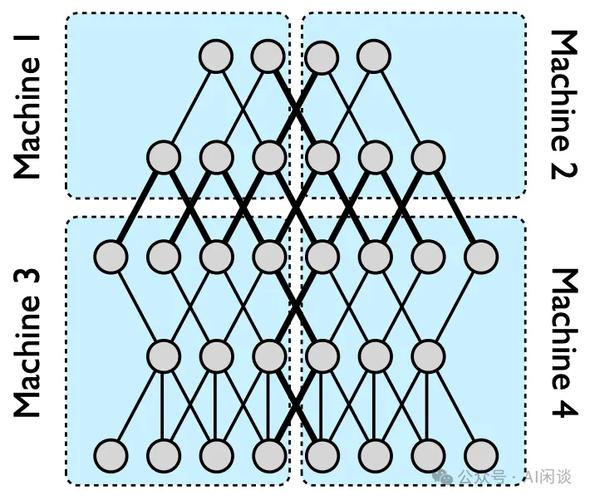
模型选择:匹配任务需求
选择合适模型架构是训练的关键一步,魔塔社区中,成员们根据不同任务推荐模型类型,对于简单分类问题,逻辑回归或决策树足够高效;而复杂任务如自然语言处理,需转向深度学习模型如Transformer或LSTM,社区资源库常提供预训练模型,例如基于BERT的变体,可直接微调节省时间,考虑模型复杂度——过于复杂的模型易导致过拟合,而简单模型可能欠拟合,在魔塔平台,试用不同架构并通过基准测试比较性能是常见做法,个人观点是,初学者从轻量级模型开始,逐步升级,避免资源浪费,社区讨论组中,专家分享案例:比如用卷积神经网络处理视觉数据,能快速收敛。
训练过程:迭代优化与监控
训练阶段涉及将数据输入模型,调整参数以最小化误差,魔塔社区倡导分步进行:先划分数据集为训练集、验证集和测试集(比例建议70:15:15),启动训练时,设置超参数如学习率和批次大小,学习率过高可能导致震荡,过低则延长训练时间;社区工具如自动调参插件能辅助优化,使用GPU加速训练,魔塔资源中心提供云端算力租赁选项,监控损失函数和准确率曲线——如果验证集表现下降,表明过拟合,需早停或添加正则化,训练中,定期保存检查点,防止意外中断,社区经验是,迭代训练周期(epoch)不宜过多,一般10-50次足够,视数据规模而定,过程中,日志记录帮助诊断问题;魔塔论坛上,成员分享可视化工具跟踪进度。

评估和优化:确保模型可靠性
训练后,评估模型性能不可或缺,在魔塔社区,标准指标包括准确率、召回率和F1分数,具体取决于任务类型,分类模型用混淆矩阵分析错误;回归模型看均方误差,测试集结果反映泛化能力——如果表现差,需回溯数据或模型选择,优化方法包括微调超参数、集成多个模型或使用迁移学习,社区案例显示,加入对抗训练能提升鲁棒性,部署前,进行A/B测试验证实际效果,魔塔环境鼓励开源精神:发布模型到共享库,获取反馈迭代改进,个人观点是,模型优化永无止境;社区协作加速创新,但需平衡时间与收益,避免完美主义陷阱。
魔塔社区的AI模型训练之旅充满挑战与乐趣,通过亲身实践,我体会到数据质量和社区支持的核心作用;持续学习新技术,保持开放心态,能解锁更多可能性,加入讨论,分享您的经验,共同推动AI进步。(字数:1180字)

 13888888888
13888888888

 点击咨询
点击咨询 